Em estatística, uma transformação de potência é uma família de funções que são aplicadas para criar a transformação monotônica de dados usando funções de potência. Esta é uma técnica de transformação de dados útil usada para estabilizar a variância, tornar os dados mais semelhantes à distribuição normal, melhorar a validade das medidas de associação (como a correlação de Pearson entre as variáveis) e para outros procedimentos de estabilização de dados.
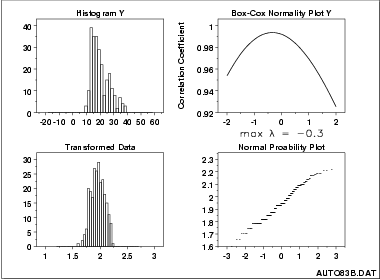
Tanto a forma linear quanto a logarítmica são dois casos particulares de uma família mais extensa de transformações não-lineares. A transformação de potência é definida como uma função de variação contínua, em relação ao parâmetro de potência λ (lambda), ou seja, xλ. Uma classe geral de transformação que pode ser utilizada é a de Box-Cox, definida por:
\(f_\lambda(x)=\frac{x^\lambda-1}{\lambda}\) para \(\lambda\neq0\)
\(f_0(x)=log(x)\) para \(\lambda=0\)
A transformação de Box-Cox recebeu o nome dos estatísticos que a formularam, George E. P. Box y David Cox, em artigo de 1964 (“An Analysis of Transformations”). É bastante conhecida no meio econométrico e usada para enfrentar problemas de heterocedasticidade (quando o modelo de hipótese matemático apresenta variâncias para Y e X(X1, X2, X3,…, Xn) não iguais para todas as observações) e/ou falta de normalidade.
A escolha do melhor valor de lambda pode ser automatizada. Na linguagem R, sua implementação pode ser feita através do pacote “forecast”, através da função “BoxCox.lambda()”. Veja esse exemplo de uso envolvendo modelagem e previsão de série temporal usando modelo ARIMA:
# Importar bibliotecas require(forecast) # Calcular melhor valor de lambda para a série temporal lambda = BoxCox.lambda(serie_temporal) # Calcular modelo ARIMA via decomposição STL e fazer previsão para os próximos 5 tempos model = stlf(serie_temporal, lambda = lambda, h = 5, method = 'arima', s.window = 'periodic') # Selecionar previsão forecast = model$mean
No python, o pacote “scipy” possui a função “boxcox()” para transformar os dados e “inv_boxcox()” para inverter a transformação – mais informações na documentação do scipy (stats.boxcox e stats.inv_boxcox). Veja esse exemplo de uso baseado no script em R:
# Importar bibliotecas from scipy.stats import boxcox from scipy.special import inv_boxcox from pmdarima.arima import ARIMA # Calcular melhor valor de lambda para a série temporal serie_temporal2, lambda_boxcox = boxcox(serie_temporal) # Calcular modelo ARIMA model = auto_arima(serie_temporal) # Fazer previsão para os próximos 5 tempos forecast = model.predict(n_periods=5) # Inverter transformação final_forecast = inv_boxcox(forecast[0], lambda_boxcox)
É indicado deixar o valor de lambda restrito entre 0 e 1 (ou 0,5 e 1,0 se os dados incluíssem valores de zero), caso contrário podem resultar em previsões muito erráticas (principalmente quando os valores de lambda estavam abaixo de 0,5).
Fontes
- Wikipedia – Power transform
- How Could You Benefit from a Box-Cox Transformation?
- Uma nota sobre a transformação Box-Cox
- R-bloggers – Does seasonally adjusting first help forecasting?
- Machine Learning Mastery – How to Use Power Transforms for Time Series Forecast Data with Python
- mode – Forecasting in Python with Prophet

3 comments