Dentre os pacotes disponíveis no python para trabalhar com previsão estatística, estão o statsmodel (que possui a classe arima_model) e o pmdarima (renomeado de pyramid desde a versão 1.0.0, para não confundir com o framework web Pyramid). A classe ARIMA do pmdarima permite a sazonalidade opcionalmente, enquanto que a classe ARIMA do statsmodels ainda não tem nenhum componente sazonal.
O pmdarima é essencialmente um wrapper Python & Cython (ou seja, tem um pouco de código C) de diversas bibliotecas estatísticas e de aprendizado de máquina (statsmodels e scikit-learn), e opera generalizando todos os modelos ARIMA em uma única classe (diferente de statsmodels). Também é projetada para se comportar da mesma forma que o bem conhecido auto.arima do R – tanto que faz referência à documentação do pacote forecast do R, desenvolvido por Rob Hyndman. Para conhecer mais sobre o modelo ARIMA, clique no link.
A função “auto_arima” opera um pouco como uma pesquisa de grade (“grid search” ou “hyperparameter optimization”), na qual ele tenta vários conjuntos de parâmetros p e q (também P e Q para modelos sazonais), selecionando o modelo que minimiza o AIC (ou BIC, ou qualquer critério de informação selecionado). Para selecionar os termos de diferenciação, auto_arima usa um teste de estacionariedade (como um teste aumentado de Dickey-Fuller) e sazonalidade (como o teste Canova-Hansen) para modelos sazonais. Mais informações na parte de dicas da documentação (links no final do post).
O pmdarima tem dependência de alguns pacotes (Numpy, SciPy, Scikit-learn, Pandas e Statsmodels), podendo ser instalado através do comando “pip install pmdarima” – pip3 para python 3. Caso dê alguma mensagem de erro relacionada a algum pacote durante a execução dos scripts, experimente atualizar o respectivo pacote através do comando “sudo pip3 install NOME_DO_PACOTE –upgrade”.
Exemplos de uso
O objetivo desse post é o de usar a função auto_arima para obter automaticamente os melhores parâmetros do modelo e salvá-lo, para então carregá-los (usando outra função) para fazer a previsão com base nesse modelo. Serão usadas séries temporais de uma variável endógena (a ser prevista) e de uma variável exógena (para inserir informações na série original).
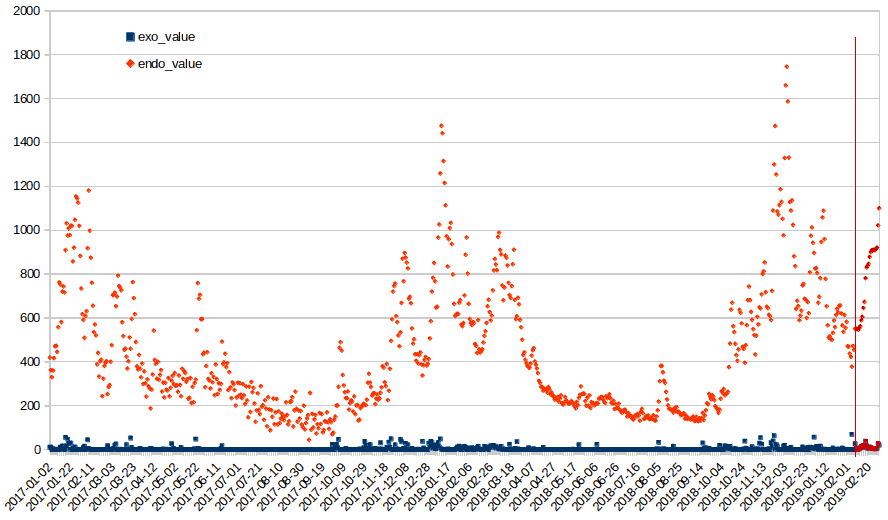
O script e os arquivos com as séries de dados estão no GitHub/arima_python (testado em python 3.5.2). Clique no link e abra o arquivo model_forecast.py para acompanhar a descrição a seguir, começando das linhas logo após as definições de classes.
Primeiramente, é preciso obter as séries temporais da variável endógena e da variável exógena (observada e prevista) de arquivos CSV. Depois, Selecionar o período de dados da variável exógena que corresponda à previsão e reformatar as variáveis para entrarem nos modelos. Também é preciso realizar a transformação de Box-Cox da série de dados endógena visando a homogeneidade/normalidade.
Foram construídas três funções para cálculo do melhor conjunto de parâmetros (p,d,q) para o modelo ARIMA (escolha a que achar mais interessante):
- via função auto_arima – recebe a série endógena e a exógena, valores mínimos e máximos dos parâmteros a serem iterados, indicação de considerar sazonalidade (seasonal=True) ou não, frequência de dados por ano (m) e mais alguns parâmetros (para mais informações, consulte o link da documentação disponível no fim do post)
- via loop com função ARIMA – montar combinações de parâmetros e calcular modelo para cada uma, escolhendo a combinação com menor valor de AIC, desconsiderando sazonalidade
- via loop com função SARIMAX – montar combinações de parâmetros e calcular modelo para cada uma, escolhendo a combinação com menor valor de AIC, considerando sazonalidade
Usando o dataset de exemplo (dados diários de 2017-01-01 a 2019-02-07, com exógenos previstos de 2019-02-08 a 2019-03-01), o modelo calculado com o segundo método gera os seguintes parâmetros:
- p,d,q = (3, 1, 2)
- lambda = -0.022610268242165006
- AIC = -501.3466801900877
Com relação à previsão, a função “predict” precisa receber o número de previsões a serem feitas (nesse caso, com base no número de valores da série da variável exógena). Além da série temporal exógena, também é possível pedir para retornar o resultado do intervalo de confiança, calculado como “(1 – alpha)%”. Como foi usada a transformação dos dados antes de calcular o modelo, agora é preciso inverter a transformação.
Finalmente, a coluna de datas previstas (gravada na separação de dados observados e previstos) é usada como índice para os valores previstos (já que possuem o mesmo número de elementos) para formar uma dataframe, que é gravada para um arquivo CSV.
Salvando, carregando e atualizando modelo
Depois que você acerta seu modelo e está pronto para começar a fazer previsões em seu ambiente de produção, você pode salvar seu ARIMA em disco. Isso pode ser interessante no caso de suas operações estarem separadas em parte de desenvolvimento do modelo e operação do modelo para gerar previsões. Você pode salvar o objeto python “arima_model” calculado em um arquivo. Dentre as informações gravadas no arquivo, estão os parâmetros “p,d,q”, os coeficientes calculados (ma1, ar1, ar2, … por exemplo), as séries usadas das variáveis endógena e exógena e outras informações.
Serialização (“serialization”) é um termo de programação orientada a objeto que indica o processo de transformar um objeto na memória em um fluxo de bytes, para que você possa armazená-lo em disco ou enviá-lo pela rede. No python, um pacote usado com esse fim é o “pickle”, que tem dois métodos principais. O primeiro é o “dump”, que copia um objeto para um objeto de arquivo, e o segundo é o “load”, que carrega um objeto de arquivo para um objeto. Você pode copiar um ou mais objetos para um mesmo arquivo, assim como carregá-los, bastando apenas saber repetir o comando sequencialmente conforme feito no script.
Caso a série temporal receba novos valores observados, suas previsões se desviarão e você precisará atualizar o modelo com os novos valores. Uma solução é re-ajustar (“refit”) o ARIMA obtido do auto_arima com os novos dados – ou seja, manter os parâmetros “p,d,q” e alterar somente os coeficientes (ma1, ar1, ar2, … por exemplo).
O “refit” é interessante para séries muito longas (acima de milhares de valores), quando o esforço computacional de recalcular o modelo é muito grande frente ao ganho deviso à inclusão de novos dados. Para isso, você deverá usar a seguinte função:
arima_model.add_new_observations(self.endo_obs_new,exogenous=self.exo_obs_new)
Onde “arima_model” é o objeto do seu modelo e as séries com novos valores das variáveis endógena e exógena são os argumentos da função “add_new_observations()”. Esse tipo de previsão é conhecida como “out-of-sample”. Caso não sejam inseridos novos valores, a função responsável pela previsão (“predict”) vai usar a mesma série que foi utilizada para gerar o modelo (salva no objeto). Nesse caso, é conhecida como “in-sample”. Mais informações no item “Refreshing your ARIMA models” da documentação.
Fontes
- Quick start example – pmdarima/auto_arima
- Digital Ocean – A Guide to Time Series Forecasting with ARIMA in Python 3
- Documentação pmdarima – auto_arima
- Documentação pmdarima – ARIMA
- Documentação pmdarima – Tips and tricks
- Documentação StasModels – SARIMAX
- Stackoverflow – Predict from estimated ARIMA model with new data