O Prophet é um pacote para R e Python usado em produção no Facebook (daí o nome do pacote, fbprophet). Ele implementa o algoritmo de previsão de séries temporais, programado para detectar automaticamente os padrões sazonais de uma série de input. Contudo, é possível customizar alguns inputs de parâmetros manualmente, como indicar a presença de períodos sazonais (semanal ou anual), feriados e changepoints.
No artigo em que os autores descrevem seus métodos (Taylor & Letham, 2017), observa-se uma abordagem prática para a previsão “em escala”, que combina modelos configuráveis com análises de desempenho analíticas em loop. É usado um modelo de regressão modular com parâmetros interpretáveis que podem ser intuitivamente ajustados por analistas com conhecimento de domínio sobre as séries temporais. Segundo a própria equipe de desenvolvimento, o Prophet funciona melhor com séries temporais de frequência diária, com pelo menos um ano de dado, sendo robusto a dados ausentes (NA), mudanças na tendência e outliers. Caso queira usar outra frequência, ela deve ser indicada dentro da função “Prophet()” como “freq=” – por exemplo, W para semanal.
Os pacotes para R e Python são apenas uma simples interface para cálculos realizados em Stan. Stan é uma plataforma de última geração para modelagem estatística e computação estatística de alto desempenho, toda feita em software livre.
Implementação em python
O pacote e todas suas dependências podem ser instaladas através do pip, sendo recomendado instalar dois pacotes antes:
pip install pystan
pip install plotly
pip install fbprophet
O prophet segue o modelo de API do sklearn. Cria-se uma instância da classe prophet e depois são chamados seus métodos de ajuste e previsão. A entrada para o Prophet é sempre um dataframe com duas colunas:
- datas (ds) – em um formato esperado pelos Pandas, idealmente AAAA-MM-DD para uma data ou AAAA-MM-DD HH: MM: SS para um registro de data e hora;
- dados (y) – numérica e representando a medida que deve ser prevista.
As colunas devem se chamar “ds” para as datas e “y” para os dados. Um arquivo de exemplo é dado pelo tutorial (link no fim do post).
As previsões são então feitas em um dataframe com uma coluna contendo as datas para as quais uma predição deve ser feita. Você pode obter um dataframe que estenda para o futuro um número específico de dias usando o método auxiliar “Prophet.make_future_dataframe”. Por padrão, ele também incluirá as datas do histórico, o que é útil para observar também o ajuste do modelo.
Veja um exemplo de implementação completa no GitHub (script prophet_simple.py).
A saída da previsão será uma dataframe contendo as seguintes colunas, cada uma com seus respectivos limites inferior e superior:
- ds – data com o modelo calculado (pode ser observado ou previsto)
- yhat – valor calculado
- trend – tendência
- additive_terms – termos aditivos
- weekly – sazonalidade semanal
- yearly – sazonalidade anual
- multiplicative_terms – termos multiplicativos
É possível fazer um gráfico contendo a série observada junto com a modelada e sua previsão, contendo os limites superior e inferior de incertezas, simplesmente chamando o método “Prophet.plot”. Também pode-se fazer um gráfico contendo as componentes da previsão através do método “Prophet.plot_components” – tendência e componentes sazonais anual e semanal.
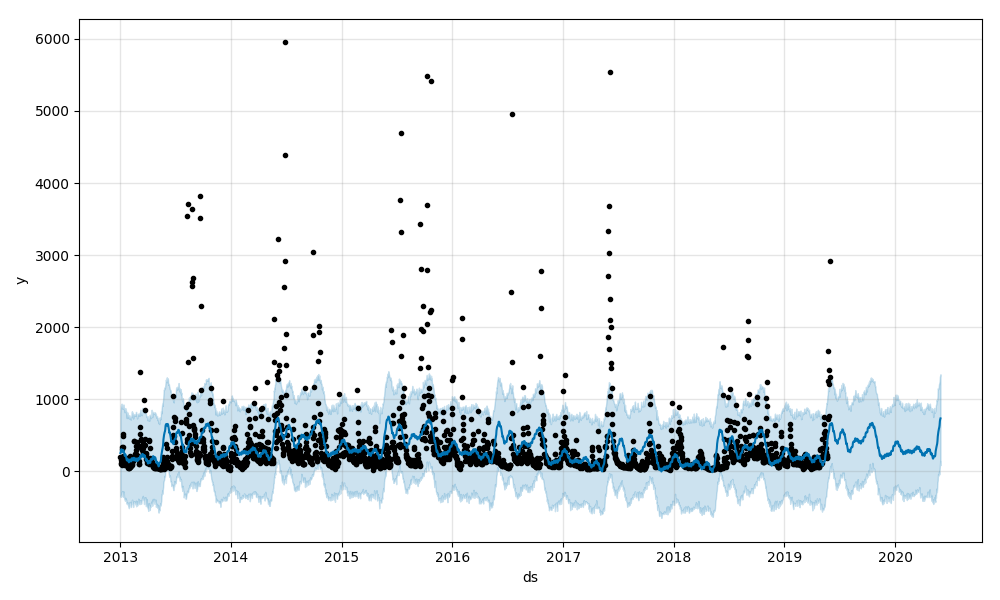
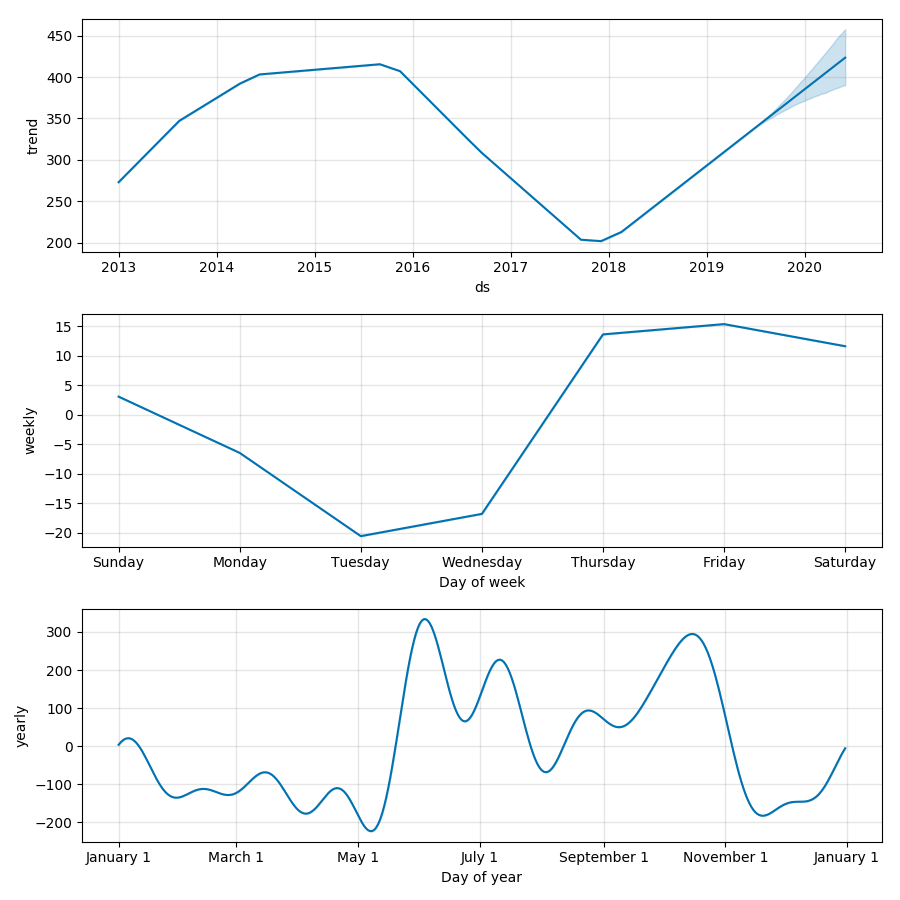
Em analogia aos modelos (S)ARIMAX, é possível adicionar um regressor externo atraves do método “prophet.add_regressor”. Veja um exemplo no GitHub (script prophet_regressors.py).
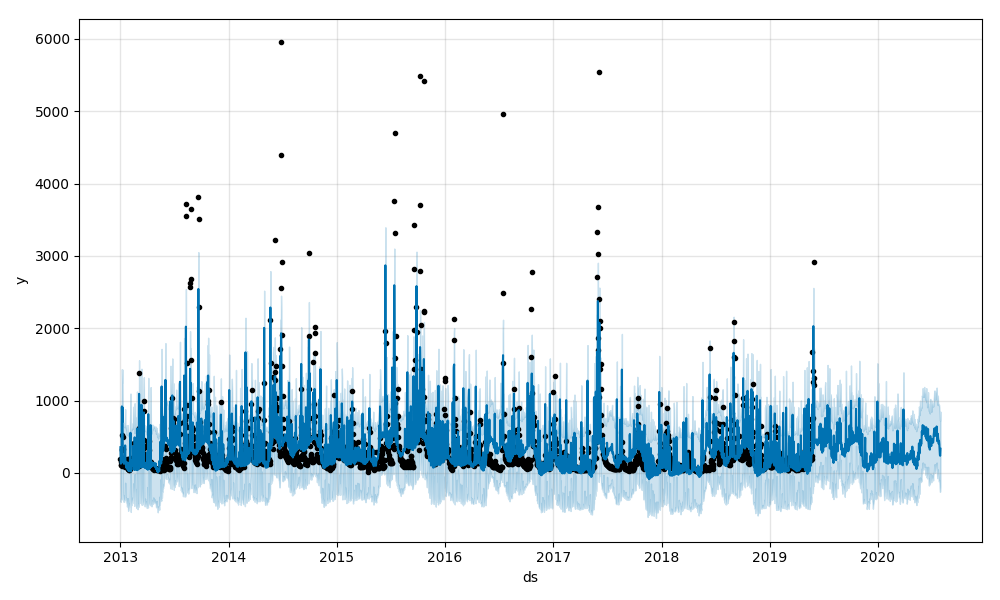
Comparando-se-se os gráficos gerados, é possível ver que o novo modelo com regressores externos acompanha bem mais a série de valores observados, mas ainda não detecta os outliers. Muitas séries têm mudanças abruptas em seu comportamento.
Por padrão, o prophet detecta automaticamente pontos de mudança brusca e permite que a tendência se adapte adequadamente. No entanto, se você deseja ter um controle mais preciso sobre esse processo (por exemplo, se o modelo perdeu uma alteração de taxa ou está super ajustando alterações de taxa no histórico), há vários argumentos de entrada que você pode usar. Veja esse exemplo, usando o valor padrão:
m = Prophet(changepoint_prior_scale=0.05)
Tendência
Por padrão, o Prophet usa um modelo linear para sua previsão. Ao prever o crescimento, geralmente há um ponto máximo atingível chamado de “carrying capacity” (capacidade de carga), onde a previsão deve saturar. Também é possível fazer previsões usando um modelo de tendência de crescimento logístico, com uma capacidade de carga especificada.
A capacidade de carga deve ser definida em uma coluna, por exemplo:
m = Prophet(growth="linear") # linear (padrão)
m = Prophet(growth="logistic") # logístico
df['cap'] = 8.5
Aqui, ele foi definido como uma constante para toda a série, mas pode ser gerado um número para cada elemento – por exemplo, analisando-se dados de mercado, se ele está em crescimento, pode ser utilizada uma sequência crescente.
Sazonalidade
As sazonalidades são estimadas usando uma soma parcial de Fourier. O número de termos na soma parcial (a ordem) é um parâmetro que determina a rapidez com que a sazonalidade pode mudar. Os valores padrão geralmente são apropriados, mas podem ser aumentados quando a sazonalidade precisa ajustar-se a alterações de maior frequência e, geralmente, ser menos suave. O valor padrão é “yearly_seasonality=10”, mas pode ser desligada, conforme o exemplo a seguir:
m = Prophet(yearly_seasonality=False)
Por padrão, o Prophet ajustará sazonalidades semanais e anuais, se a série temporal tiver mais de dois ciclos de duração, e também à sazonalidade diária de uma série temporal sub-diária. Você pode adicionar outras sazonalidades personalizadas (mensal, trimestral, horária) usando o método “add_seasonality”. Seus parâmetros são: “name” (nome), “period” (período da sazonalidade, em dias) e “fourier_order” (ordem de Fourier).
m = Prophet(yearly_seasonality=False,
growth="linear")
m.add_seasonality(name="yearly",
period=365.25,
fourier_order=10)
Esses são os valores padrão, sem definir o parâmetro “yearly_seasonality” ou considerando “yearly_seasonality=10” para sazonalidade anual; para a sazonalidade semanal, usa uma ordem de Fourier de 3. Veja uma sugestão de nomes (pode ser qualquer palavra) e o respectivo período:
name="yearly", period=365.25
name="quarterly", period=365.25/4
name="monthly", period=30.5
name="weekly", period=7
name="daily", period=1
É possível adicionar mais de uma sazonalidade, sendo que a ordem de aplicação delas é importante. Uma aplicação de sazonalidade anual pode “travar” variações diárias mais expressivas em uma série diária.
Com relação ao parâmetro “fourier_order” (sim, tem a ver com a série de Fourier), uma ordem maior significa que temos termos de frequência mais alta e, assim, conseguiremos ajustar padrões de sazonalidade mais complexos e em rápida mudança. A desvantagem de usar uma ordem muito alta é que são mais termos no modelo e, portanto, o overfitting se torna um risco.
O valor padrão de 10 normalmente é apropriado para sazonalidade na escala de um ano. Se parecer que o seu efeito de sazonalidade muda muito rapidamente e a estimativa do prophet não é capaz de capturar tudo, então tente aumentar a ordem.
Em alguns casos, a sazonalidade pode depender de outros fatores, como um padrão sazonal semanal diferente durante o verão do que durante o resto do ano ou um padrão sazonal diário diferente nos fins de semana em comparação aos dias da semana. Esses tipos de sazonalidades podem ser modelados usando sazonalidades condicionais.
Primeiro, adicionamos uma coluna booleana ao dataframe que indica se cada data é durante a temporada ou fora de temporada. Em seguida, desabilitamos a sazonalidade semanal integrada e a substituímos pelas sazonalidades semanais que têm essas colunas como uma condição especificada. Isso significa que a sazonalidade será aplicada somente às datas em que a coluna “condition_name” é “True”. Devemos também adicionar a coluna ao futuro dataframe para o qual estamos fazendo previsões.
Diagnóstico
O Prophet inclui a funcionalidade de validação cruzada (“cross validation”) de séries temporais para medir o erro de previsão usando dados históricos. Isso é feito selecionando pontos de corte no histórico e, para cada um deles, ajustando o modelo usando dados apenas até esse ponto de corte. Assim, comparam-se os valores previstos com os valores reais.
A função “cross_validation” faz a análise automaticamente através de uma série de cortes. Para isso, especifica-se o horizonte de previsão (“horizon”) e depois, opcionalmente, o tamanho do período de treinamento inicial (“initial”) e o espaçamento entre as datas de corte (“period”). Por padrão, o período de treinamento inicial é definido como três vezes o horizonte e os cortes são feitos a cada meio horizonte.
A saída é um dataframe com os valores reais y e os valores previstos fora da amostra, em cada data de previsão simulada e para cada data de corte. Uma previsão é feita para cada ponto observado entre corte e corte+horizonte. Este dataframe pode então ser usado para calcular as medidas de erro entre yhat e y.
O exemplo a seguir é para avaliar o desempenho da previsão em um horizonte de 365 dias (1 ano), começando com 730 dias (2 anos) de dados de treinamento no primeiro ponto de corte e, depois, fazendo previsões a cada 180 dias (1/2 ano). Em uma série temporal diária de 6 anos e meio, isso corresponde a 6 previsões totais.
from fbprophet.diagnostics import cross_validation
df_cv = cross_validation(m, initial='730 days', period='180 days', horizon = '365 days')
print(df_cv)
A função “performance_metrics” pode ser usada para calcular algumas estatísticas úteis do desempenho de previsão: erro quadrático médio (MSE), erro quadrático médio (RMSE), erro absoluto médio (MAE), erro percentual absoluto médio (MAPE) e cobertura das estimativas “yhat_lower” e “yhat_upper”. Eles são calculados em uma janela contínua das previsões em df_cv após classificação por horizonte (ds menos corte). Por padrão, 10% das previsões serão incluídas em cada janela, mas isso pode ser alterado com o argumento “rolling_window”.
from fbprophet.diagnostics import performance_metrics
df_p = performance_metrics(df_cv)
print(df_p)
from fbprophet.plot import plot_cross_validation_metric
plot_cross_validation_metric(df_cv, metric='mape').savefig('test_mape.png')
As métricas podem ser visualizadas com a função “plot_cross_validation_metric”, com o nome da métrica no argumento “metric”. Os pontos mostram o erro percentual absoluto para cada previsão, com uma linha azul mostrando a média da métrica, tomada em uma janela rolante dos pontos.
Fontes
- Prophet vs forecast vs mafs: Qual o melhor pacote para séries temporais?
- Taylor SJ, Letham B. 2017. Forecasting at scale. PeerJ Preprints 5:e3190v2 https://doi.org/10.7287/peerj.preprints.3190v2
- Prophet – Quick start
- GitHub/facbook/prophet – multivariate modeling
- GitHub/facbook/prophet – Where to pass regressor using add_regressor function?
- Prophet – Seasonality, Holiday Effects, And Regressors
- Pacote Prophet no R – documentação (removida do CRAN)