O sistema de modelagem numérica para previsão de tempo WRF (Weather Research and Forecasting) é usado tanto para operação dos centros meteorológicos como para as pesquisas atmosféricas. Ele foi desenvolvido por vários órgãos de pesquisa e desenvolvimento, dentre eles o NCAR (National Center for Atmospheric Research), o NOAA (National Oceanic and Atmospheric Administration), o NCEP (National Center for Environmental Prediction) e o UCAR (University Corporation for Atmospheric Research). Atua em mesoescala e microescala, em aplicações com escalas de dezenas de metros a centenas de quilômetros.
O WRF suporta paralelismo e pode ser instalado em diferentes plataformas operacionais (como no Linux) e possui uma comunidade de usuários relativamente grande e atuante. Além disso, é um software de domínio público e está disponibilizado gratuitamente na internet para dowload, com comunidade atuante.
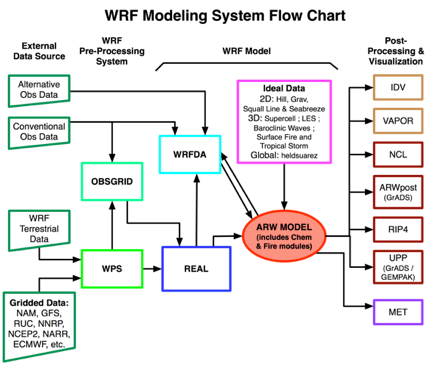
Os principais componentes do WRF são:
- Pré-processamento: WRF Preprocessing System (WPS), que é um conjunto de subsistemas que preparam os dados de entrada para a simulação: geogrid (define o domínio do modelo e interpola os dados terrestres para as grades), ungrib (extrai os campos meteorológicos do formato GRIB necessários para iniciar o modelo) e metgrid (interpola horizontalmente os campos meteorológicos extraídos pelo ungrib para as grades do modelo definida pelo geogrid);
- Inicialização (casos “real” ou “ideal”);
- Execução do modelo propriamente dito, com dois principais solucionadores dinâmicos: o núcleo ARW (Advanced Research WRF) e o núcleo NMM (Nonhydrostatic Mesoscale Model);
- Pós-processamento (ARWpost): converte as saídas do modelo para um tamanho e formato que permite serem visualizados por aplicativos gráficos;
Seguem os procedimentos de instalação do WRF versão 3.9.1 em uma máquina virtual com Linux Debian. A parte mais problemática é acertar a instalação das bibliotecas e dependências nas versões certas, assim como a definição correta de algumas variáveis de ambiente. O fórum do WRF é uma ferramenta muito útil para tirar dúvidas de erros que venham a aparecer.
Instalação
Foi criada uma máquina virtual (VM) Debian 64-bits no VirtualBox no formato VMDK, com 2048 MB de memória e disco de 200 GB dinamicamente alocado. Foi instalado o sistema operacional Linux Debian 9.3.0 64-bits (kernel 4.9.0-4-amd64). Nele, foi instalado o programa sudo e incluído o usuário comum, além de configurada a rede para acesso pelo hospedeiro (veja mais no post sobre máquina virtual). O WRF a ser instalado aqui está na versão 3.9.1. Alternativa: instalação em CentOS 7Linux 3.10.0-514.el7.x86_64
Atualização: apesar da instalação ter usado processador AMD, é recomendável usar hardware com Intel, pois ele possui um núcleo otimizado para cálculos em ponto flutuante e algumas flags são otimizadas para esse processador. Atualmente, recomenda-se usar 16 GB de memória, mas 4 GB já são suficientes para testes.
Existem vários tutoriais disponíveis na internet, que acabam se complementando em alguns macetes para instalação:
- UCAR – Compitaltion tutorial
- UCAR – Online Tutorial
- UCAR – User’s guides
- MetClim – WRF installation on a Linux machine
- Manual de instalação, compilação e execução do modelo de mesoescala WRF no ICEA
- Enviroware – Installing and running WRF 3.8 on Linux Ubuntu
- INPA – Configuring WRF 3.8 on Ubuntu Server 16.04 (YouTube)
- Thiago Gomes Veríssimo – Instalação do WRFV3 e Rodando o WRFV3
Boa parte dos softwares e bibliotecas estão disponíveis no repositório do Debian. No entanto, é melhor usá-lo somente para os pacotes mais básicos e deixar os programas mais importantes (relacionados com a leitura dos arquivos de dados) para baixar e compilar separadamente. As condições iniciais e de contorno utilizadas no modelo estão no formato GRIB2 (geralmente da segunda versão do código General Regularly-distributed Information in Binary), que é um padrão da WMO (World Meteorological Organization) para o armazenamento de campos regularmente distribuídos (por exemplo, pontos de grade).
Dos tutoriais disponíveis, escolhi o que permitesse maior automação de tarfeas possível (o último da lista) e usei os outros para complementar alguns erros que foram aparecendo nas tentativas de instalação. Os scripts e namelists mencionados a seguir estão disponíveis no GitHub/wrf_install – baixe-os no diretório definido para instalação e execute-os quando for informado ao longo do tutorial (não esquecer de torná-los executáveis com o comando “chmod +x *.sh”).
1) Instalar os compiladores de Fortran e C, instalador, descompactadores, etc:
sudo apt-get update
sudo apt-get install gfortran gcc make csh tcsh g++ cpp flex bison curl m4 perl zip unzip zlib1g-dev
# Programas úteis que não vêm "de fábrica"
sudo apt-get install sudo locate htop screen
# CentOS
#sudo yum -y install make csh flex bison curl perl zip unzip gcc-gfortran gcc-c++ bzip2
#sudo yum -y install mlocate rsync screen htop nano wget
2) Definir diretório de instalação e criar pastas:
ROOT="/home/operacao"
mkdir -p "$ROOT/WRF/Downloads" # Pacotes baixados
mkdir -p "$ROOT/WRF/LIBRARIES" # Bibliotecas instaladas
mkdir -p "$ROOT/WRF/data" # Dados de entrada
mkdir -p "$ROOT/WRF/output" # Dados de saída
As bibliotecas serão instaladas nesse caminho (em vez do tradicional “/usr/local/bin”). Caso reinstale o sistema em outro caminho posteriormente, é possível criar um link simbólico apontando para a nova pasta: cd /home;
ln -s operacao /data (por exemplo).
3) Definir as variáveis de ambiente (inclua o texto do arquivo “bashrc_wrf” no final do arquivo oculto .bashrc do usuário que vai rodar o WRF) e atualize as variáveis para a sessão atual:
cat WRF/bashrc_wrf >> ~/.bashrc
source ~/.bashrc
4) Escolher as versões dos programas e testar se o link é válido – edite o arquivo para alterar a versão e o link (se for o caso) e execute conforme segue:
./check_links.sh
Caso algum link tenha retornado algum valor diferente de zero, ele pode estar indisponível ou inválido. Entre na raiz do site, busque um novo caminho ou versão, altere no script e refaça o teste.
5) Baixar e instalar as bibliotecas (preferencialmente uma a uma, por segurança, descomentando a função seguinte e recomentando a anterior):
./libraries.sh
Caso tenha realizado alguma mudança de versão e link anteriormente, elas também devem ser feitas nesse script.
6) Baixe, configure e compile o WRF (confira a versão do WRF a ser utilizada no nome da variável global no início do arquivo):
./wrfv3.sh
# Conferir se rodou certo
ls -lh WRFV3/main/*.exe
O script “configure” cria o arquivo de configuração do WRF, no qual ele checa os recursos computacionais e oferece opções para a configuração do WRF. As opções escolhidas foram: “33 GNU (gfortran/gcc) (smpar)” e “1 Basic”. A sigla SMpar (Shared-Memory) é usada no caso de um computador com vários núcleos (precisa do openMP), DMpar (Distributed-Memory) é para o caso de um cluster de computadores (precisa do MPI) e Serial é para um só núcleo.
Deve demorar por volta de 20 minutos para compilar o código. Acompanhe o andamento através do comando “tail -f WRFV3/compile.log”.
Devem ser gerados quatro programas no sub-diretório “main”: ndown.exe, tc.exe, real.exe e wrf.exe. Caso contrário, veja o arquivo de log gerado (compile.log) e busque por erros. Para compilar novamente, o script já contém a linha responsável por apagar os arquivos temporários gerados (./clean -a); descomente-a e comente as linhas referentes a baixar e extrair o arquivo do site do UCAR.
7) Baixar, configurar e compilar o WPS (confira a versão do WPS; use a opção “1. Linux x86_64, gfortran” na configuração):
./wps.sh
# Edite o arquivo para incluir falg "-lgomp" na variável WRF_LIB
nano WPS/configure.wps
cd $WRF/WPS; ./compile >& compile.log ; cd ..
# Conferir se rodou certo
ls -lh geogrid/src/geogrid.exe ungrib/src/ungrib.exe metgrid/src/metgrid.exe
Demora por volta de 1 minuto para compilar o WPS (acompanhe usando “tail -f WPS/compile.log”). São criados os seguintes arquivos: geogrid.exe (define o tamanho e localização do domínio), ungrib.exe (extrai os campos meteorológicos dos arquivos GRIB) e metgrid.exe (interpola horizontalmente os campos meteorológicos para a grade simulada definida). No diretório WPS, existem links para esses arquivos.
Se os binários (e os links) não forem gerados, buscar no arquivo compile.log por erros – descomente a linha “./clean -a” e comente as linhas do arquivo wps.sh referentes ao download e extração para rodar o script novamente. Se aparecer um erro do tipo “wrf_io.f:(.text+0xff4): undefined reference to `GOMP_loop_runtime_start'”, comente também a linha de compilação e edite o arquivo “configure.wps” para incluir a flag “-lgomp” no final da variável “WRF_LIB”. Só então rode a linha de compilação.
8) Baixar, configurar e compilar o ARWpost:
./arwpost.sh
# Edite o arquivo para incluir "-lnetcdff" no final da linha com "ARWpost.exe"
nano $WRF/ARWpost/src/Makefile
# Edite o arquivo para incluir "-cpp" depois de "FC = gfortran"
nano $WRF/ARWpost/configure.arwp
cd $WRF/ARWpost; ./compile >& compile.log ; cd ..
# Conferir se rodou certo
ls -lh src/ARWpost.exe
Durante a configuração, escolher a opção “3. PC Linux i486 i586 i686 x86_64, gfortran compiler”. Não sei se precisa, mas é bom fazer incluir o parâmetro “-lnetcdff” no final da linha com “ARWpost.exe” no arquivo ARWpost/src/Makefile. Se de um erro do tipo “Error: Invalid character in name at (1)”, edite o arquivo “configure.arwp” para incluir o parâmetro “-cpp” depois de “FC = gfortran” e só então compile novamente.
9) Na pasta raiz, baixar e descompactar o arquivo contendo o conjunto de dados geográficos de terreno (Download Complete Dataset) – tem quase 3GB compactado e 49 GB descomprimido:
wget http://www2.mmm.ucar.edu/wrf/src/wps_files/geog_complete.tar.gz
tar -vzxf geog_complete.tar.gz
# Caso precise de algum arquivo faltante, exigido ao rodar o "geogrid.exe"
#cd WRF/geog
#wget http://www2.mmm.ucar.edu/wrf/src/wps_files/nlcd2011_imp_ll_9s.tar.bz2 http://www2.mmm.ucar.edu/wrf/src/wps_files/nlcd2011_can_ll_9s.tar.bz2
#tar -jxvf nlcd2011_imp_ll_9s.tar.bz2 ; tar -jxvf nlcd2011_can_ll_9s.tar.bz2
O conjunto de dados da superfície terrestre foi obtido através de mapeamento por satélite. As resoluções dos dados são variadas (1º, 10′, 5′, 2′ e 30”) e contêm informações como albedo da superfície mensal, fração da vegetação mensal, categoria de uso da terra, etc.
Teste
Existe um tutorial no site do UCAR que usa as configurações default do WRF para rodar um exemplo na costa leste do EUA em Janeiro de 2000.
1) Baixar os dados (disponíveis no tutorial do UCAR) e extrai-los na raiz de seus diretórios:
cd $WRF/data
wget http://www2.mmm.ucar.edu/wrf/TUTORIAL_DATA/JAN00_AWIP.tar.gz
tar -vzxf JAN00_AWIP.tar.gz
2) Criar um link para o arquivo “Vtable.AWIP” (que especifica quais variáveis serão usadas), ou criar uma nova com os mesmos padrões, e um link para os dados:
cd $WRF/WPS
ln -sf ungrib/Variable_Tables/Vtable.AWIP Vtable
#ln -sf ungrib/Variable_Tables/Vtable.GFS Vtable # Se usar dados GFS em vez do AWIP
./link_grib.csh ../data/JAN00/*
3) Definir a grade e interpolação dos dados geográficos nela (pré-processamento – geogrid):
Edite o arquivo “WPS/namelist.wps” para ficar um só domínio, definir a grade (centro, dimensão e quantidade de pontos) e a localização dos dados estáticos (geog_data_path). Caso as variáveis tenham duas ou mais “colunas”, apagar de modo a ficar somente um valor seguido de vírgula, se for o caso. Ou simplesmente copie o arquivo namelists.wps do GitHub para a pasta WPS.
Com estas definições criadas, execute o geogrid.exe:
./geogrid.exe
Deve ser criado o arquivo geo_em.d01.nc
4) Descompactar os dados meteorológicos em um formato intermediário (pré-processamento – ungrib):
./ungrib.exe
5) Interpolar os dados meteorológicos na grade definida em geogrid (pré-processamento – metgrid):
./metgrid.exe
6) Editar o arquivo “WRFV3/run/namelist.input” para acertar parâmetros de tempo e de grade (conforme arquivo do GitHub). Clique no link para ter mais informações de como montar os arquivos namelists.
7) Criar um link na pasta run dos arquivos gerados com a execução do “metgrid”:
cd $WRF/WRFV3/run
ln -sf ../../WPS/met_em* .
8) Executar o binário “real” para criar a inicialização do modelo:
./real
São gerados os arquivos com as condições iniciais (wrfinput_d01) e as codições de contorno (wrfbdy_d01) no mesmo diretório.
9) Rodar a integração numérica do modelo com o número de núcleos disponíveis:
cpuinfo=$(cat /proc/cpuinfo | grep processor | wc -l)
${MPICH}/bin/mpirun -np ${cpuinfo} ./wrf.exe
# Conferir se rodou certo
ls -lh wrfout_d01_2000-01-24_12:00:00
10) Alterar o arquivo “ARWpost/namelist.ARWpost” (conforme arquivo no GitHub) para acertar caminhos e algumas variáveis e então rodar o binário de pós-processamento:
cd $WRF/ARWpost
./ARWpost.exe
# Conferir se rodou certo
ls -lh outputExemplo.ctl outputExemplo.dat
Além desses programas, o GrADS pode ser instalado para trabalhar com arquivos GRIB – veja mais sobre o GrADS clicando no link.

Faz um post igual a este sobre como instalar e rodar o RegCM modelo climático.
Oi Thiago, vontade não me falta, assim que eu tiver tempo vou fazer. Obrigado pela dica!
muito bom!