Uma das grandes dificuldades para fazer melhores previsões de tempo e estudos da atmosfera é devido à baixa quantidade e qualidade de informações de clima disponíveis. Regiões remotas e pouco habitadas possuem poucas estações meteorológicas para coleta dessas informações, muitas vezes precisando de manutenção. Isso tudo gera séries históricas com falhas e variáveis inconsistentes. Sabendo desses problemas, diversos centros de previsão do tempo e clima vêm oferecendo produtos de reanálise (clique no link para ver alguns exemplos), que são séries de dados meteorológicos obtidos através da assimilação e nova análise de dados observados em todo o planeta.
NCEP/NCAR
O NCEP (National Centers for Environmental Prediction) em parceria com o NCAR (National Center for Atmospheric Research) disponibilizam séries históricas de reanálise desde 1948 até a atualidade com 2,5° x 2,5° de resolução espacial, o NCEP/NCAR Reanalysis Project. Esse esforço envolve a recuperação de dados de superfície terrestre, navio, radiossonda, aviões, satélites e outros dados, controle e assimilação. Para a geração dos dados de Reanalysis são usados campos globais atmosféricos e de fluxos superficiais derivados dos sistemas de previsão numérica e de assimilação de dados do NCEP/NCAR (Kalnay et al., 1996; Kistler et al., 2001).
Para baixar os arquivos do NCEP/NCAR, clique no link e escolha uma das seções (“surface”, por exemplo, para dados de superfície). Depois escolha a variárel de interesse (“Air Temperature”, por exemplo) e a frequência dos dados (quatro vezes ao dia, diária ou mensal) e então clique em “see list”. Na tela seguinte, clique novamente nessa opção para ver a lista com os arquivos de dados ou em “Make plot or subset” para fazer um mapa simples com a variável e/ou criar um arquivo para uma área e períodos selecionados.
CFSR
O CFSR (NCEP Climate Forecast System Reanalysis) foi projetado e executado como um sistema global, de alta resolução, oceano-atmosfera-terra acoplado, considerando superfície do gelo e do mar, para fornecer a melhor estimativa do estado destes domínios ligados durante o período de registro de 32 anos (janeiro de 1979 a março de 2011). A partir de março de 2011, foi criado CFSR2. Podem ser nesse do NOAA-NDCC. A resolução é de 0,5° quatro vezes ao dia e os níveis verticais são (em hPa): 1000 975 950 925 900 875 850 825 800 775 750 700 650 600 550 500 450 400 350 300 250 225 200 175 150 125 100 70 50 30 20 10 7 5 3 2.
ECMWF
O Centro Europeu de Previsão de Tempo (ECMWF) instituiu o projeto “ECMWF Re-Analysis” (ERA) possui dados desde 1950 até o presente. Era chamado de “ERA-Interim” devido ao projeto inicial de ser algo temporário, sendo substituído pelo ERA5 – veja mais no post Mapas de reanálise com python. Sua resolução espacial padrão é de 30 km e 137 níveis verticais. De modo geral, os arquivos contém dados de todo o globo, tendo a opção de recortar os limites que interessam antes de baixar os dados.
A respeito das coordenadas geográficas, elas podem vir no tradicional sistema latitude/longitude ou como pontos de grade (“gaussian grid“). Existem scripts (em Fortran, NCL e IDL) e tabelas que permitem o “Regridding” (conversão de pontos de grade para lat/lon).
– Formato NetCDF
Os dados são disponibilizados em formato NetCDF (Network Common Data Form) “.nc”. O arquivo é formado por “File Overview”, “Global Atributes”, “Dimensions” (variáveis de localização) e “Variables”. As variáveis são tempo, latitude e longitude (em pontos de grade) e as variáveis meteorológicas são compostas geralmente dos seguintes atributos:
- scale_factor – fator de escala é um número que deve multiplicar a variável
- add_offset – a compensação é o número a ser adicionado ao valor da variável
- _FillValue – o valor de preenchimento é usado para pré-preencher o espaço em disco alocado para a variável
- missing_value – escalar que indica a ausência de dados, fora do range válido (-999, por exemplo)
- units – string com caracteres para descrever a unidade de medida utilizada
- long_name – nome descritivo mais longo
- valid_range – vetor de dois números que contém o valor máximo e o valor mínimo que a variável pode assumir; esses valores podem ser definidos separadamente como valid_min e valid_max
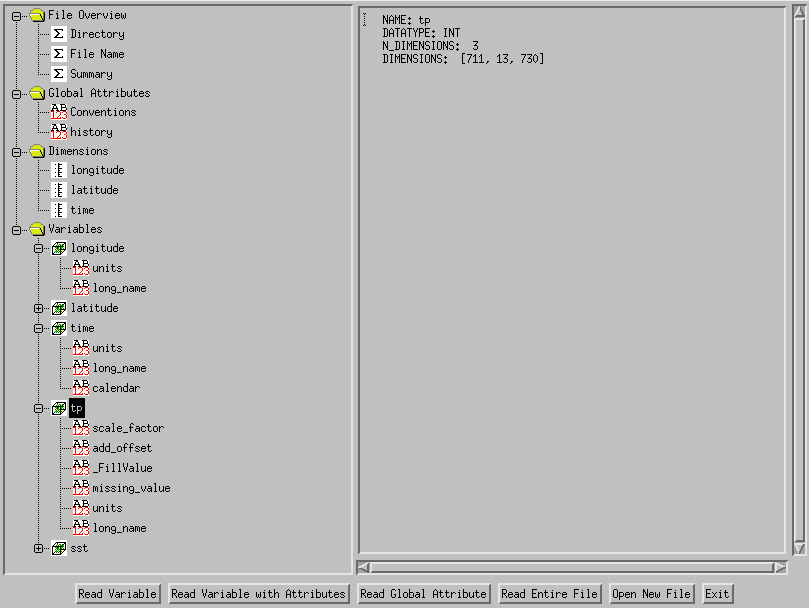
O tempo tempo geralmente é informado em número de horas desde a meia noite de 1900-01-01. Pode ser interessante mudarmos para segundos e usar como referência a Era UNIX. Se utilizarmos o comando date no terminal Linux, temos que o número de segundos desde 1970 corresponde a 0 segundos, enquanto que “date -u -d “1900-01-01 00:00:00″ +%s” vale -2208988800 segundos. Portanto, esse é, em módulo, o número de segundos entre o início da contagem utilizada e o início da Era UNIX. Veja o algoritmo de conversão a seguir em shell script:
#!/bin/bash
n_horas=$1
# Passar número de horas para número de segundos
n_segundos_desde_1900=$(($n_horas*3600))
# Descobrir número de segundos agora a partir de 1970
n_segundos_desde_1970=$(($n_segundos_desde_1900-2208988800))
# Converter esse valor para timestamp
date -u -d@$n_segundos_desde_1970 '+%Y-%m-%d %H:%M:%S'
É possível utilizar o IDL para visualização dos arquivos. Segue uma rotina para plotar os dados de temperatura como exemplo de como abrir os arquivos e ver as IDs de seus parâmetros:
dir_in = '/home/monolito/reanalise/'
file1 = dir_in + 'netcdf-web239-20140127212730-1555-11393.nc'
Nvars = 100
ncid = NCDF_OPEN(file1)
; Place the desired variables in local arrays.
for i=0, Nvars-1 do begin
vardata = NCDF_VARINQ(ncid, i)
attname = ncdf_attname(ncid,i,1)
print,i,"-->", vardata.name
natts=vardata.natts
for j=0,natts-1 do begin
attname = ncdf_attname(ncid,i,j)
NCDF_ATTGET, ncid, i, attname, attval
;print,attname,attval
endfor
ENDFOR
NCDF_CLOSE,ncid
A biblioteca coyote tem umas procedures bem interessante (clique no link para ver mais). Por exemplo, o comando “nCDF_Browser” abre uma janela para visualização dos conteúdos do arquivo.
– Formato GRIB
O formato utilizado é o GRIB (GRIdded Binary ou General Regularly-distributed Information in Binary form), um formato de dados conciso comumente usado em Meteorologia para armazenar dados climáticos históricos e de previsão – padronizado pela Comissão Organização Meteorológica Mundial para Sistemas Básicos, atualmente na versão 2 (“.grib2”).
É possível o arquivo converter para netCDF através do programa “Climate Data Operator – CDO” – no entanto, o arquivo fica bem maior. Veja mais no post sobre Edição de arquivos NetCDF com CDO.
Existem diversas rotinas para trabalhar com dados GRIB no IDL – no link, clique na rotina “GRIB_GET_VALUES” que tem um bom exemplo completo usando algumas outras rotinas. Outras rotinas estão descritas no artigo “An example of using the GRIB helper routines”, sendo que as funções utilizadas podem ser baixadas no github.
Veja esse script em IDL para visualizar parâmetros de arquivo GRIB2 usando duas funções do último link:
@grib_get_parameternames
@grib_get_record
dir_in = '/home/monolito/CFS/'
file_in = 'cdas1.t18z.pgrbhanl.grib2'
f = dir_in+file_in
print, f
p = grib_get_parameternames(f)
; Imprime lista dos parâmetros utilizados no arquivo
;print,p
for i = 1,size(p, /N_ELEMENTS) do begin
var = grib_get_record(f, i, /structure)
print, i,' = ',var.parametername,' (',var.parameterunits,') - Level ',var.level,var.pressureunits
endfor
END
– Formato HDF
Outro formato muito popular para guardar dados científicos é o HDF (Hierarchical Data Format). Na verdade, esse é o nome para um conjunto de formatos de arquivos e bibliotecas criadas para organização e armazenamento de grandes quantidades de dados numéricos. Um programa gráfico utilizado para sua visualização (semelhante ao netCDF) é o HDF Viewer, que pode ser instalado no Linux através do comando “apt-get install hdfview”. Veja um exemplo de como ler um arquivo HDF com funções IDL:
pro le_file,file,rain
sd_id=HDF_SD_START(file,/read)
; Variavel 400 x 1440 pontos (Lat X Long) a cada 0.25 x 0.25
sds_id=HDF_SD_SELECT(sd_id,0)
HDF_SD_GETDATA, sds_id, var
HDF_SD_ENDACCESS,sds_id
HDF_SD_END,sd_id
return
end
A visualização e manipulação dos dados nesses formatos também pode ser realizada pelo GrADS.
2 comments