Dentre os mais comuns formatos de arquivo para guardar dados meteorológicos, estão GRIB, netCDF e HDF. Todos eles são portáteis (podem ser manipulados em qualquer máquina/sistema operacional) e auto-descritivos (podem ser examinados e lidos por qualquer software, sem que o usuário saiba detalhes estruturais do arquivo), podendo incluir metadados. Visando atender às necessidades da comunidade científica, foram lançadas diferentes versões desses arquivos.
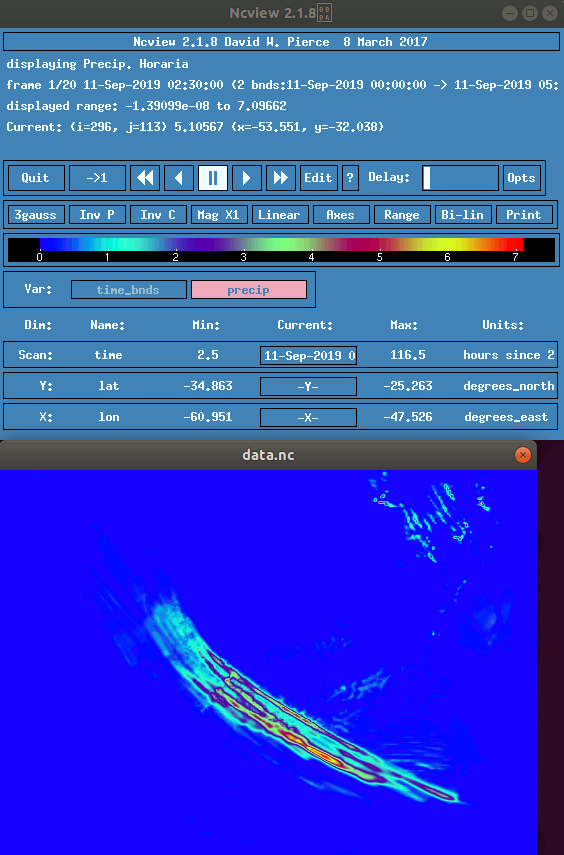
O formato NetCDF (Network Common Data Form) foi lançado em 1989 e ainda é mantido pela Unidata (UCAR/NCAR) nas versões 3 e 4. Em seu site, existem exemplos de arquivos “.nc” para serem baixados. O visualizador ncview pode ser instalado através do comando “sudo apt install ncview” e utilizado através do seguinte comando:
ncview filename.nc
O modelo de dados “clássico” é composto de dimensões, variáveis e atributos.
Uma dimensão (dimension) é um número inteiro usado para especificar o formato de uma ou mais variáveis multidimensionais contidas em um arquivo netCDF. Geralmente é usada para representar uma dimensão física real, como tempo, latitude, longitude ou altura, mas também pode ser usada para indexar quantidades mais abstratas, como número de entrada da tabela de cores, número do instrumento, par de estação-tempo ou ID de execução do modelo.
Cada dimensão possui um nome e um tamanho. Um nome de dimensão é uma sequência arbitrária de caracteres alfanuméricos (assim como o caractere sublinhado, underline e o hífen) começando com uma letra. Um tamanho de dimensão é um número inteiro positivo arbitrário ou o tamanho “UNLIMITED” (ilimitada), que pode crescer para qualquer comprimento ao longo dessa dimensão.
Uma variável (variable) representa uma matriz multidimensional de valores do mesmo tipo. Ela possui um nome, um tipo de dados e uma forma descrita por sua lista de dimensões, todas especificadas quando a variável é criada. Cada variável também pode ter valores de dados e atributos associados, que podem ser adicionados ou alterados após a criação da variável. As variáveis são usadas para armazenar a maior parte dos dados em um arquivo netCDF e são o principal componente usado pelos utilitários para identificar sub-partes de um arquivo netCDF.
Um nome de variável é uma sequência arbitrária de caracteres alfanuméricos (incluindo também underline e hífen) começando com uma letra. Nomes longos ajudam a auto-documentar um arquivo netCDF, mas as informações auxiliares sobre uma variável são melhor armazenadas em atributos de variável (discutidos abaixo) do que codificadas como parte do nome. Um tipo de dados variável é um de um pequeno conjunto de tipos de netCDF que possuem os nomes NC_BYTE, NC_CHAR, NC_SHORT, NC_LONG, NC_FLOAT e NC_DOUBLE na interface C e os nomes correspondentes NCBYTE, NCCHAR, NCSHORT, NCLONG, NCFLOAT e NCDOUBLE em a interface FORTRAN. Na notação CDL, esses tipos recebem os nomes mais simples byte, char, curto, longo, flutuante e duplo. A forma de uma variável é especificada por sua lista de dimensões – se tiver uma dimensão ilimitada, ela deverá aparecer primeiro na lista de dimensões em CDL. É possível definir variáveis sem dimensões, também chamadas de variáveis escalares.
Um atributo (attributes) deve conter informações sobre uma variável ou um arquivo netCDF inteiro. Essas informações são dados auxiliares ou dados sobre dados, análogos às informações armazenadas nos dicionários e esquemas de dados nos sistemas de banco de dados convencionais. Um atributo tem uma variável associada, um nome, um tipo de dados, um comprimento e um valor. Atributos individuais são identificados especificando uma variável e um nome de atributo.
Cada atributo é associado a uma única variável quando é criado. Os atributos para diferentes variáveis podem diferir no tipo de dados, comprimento e valores, mesmo que eles compartilhem o mesmo nome. Um atributo global é aquele que se aplica a todo o netCDF e não a qualquer variável específica. Os atributos são mais dinâmicos que variáveis ou dimensões; eles podem ter seu tipo, comprimento e valores alterados após serem criados.
Usando python para ler/plotar/gravar um arquivo netCDF
Um dos pacotes do python para leitura e escrita de netCDF é o netCDF4, que pode ser instalado no conda usando:
conda install netCDF4
Ao importar o conteúdo de um arquivo netCDF para uma variável chamada “dataset”, o formato do arquivo pode ser impresso acessando-se o método “dataset.file_format”. Uma lista das dimensões pode ser acessada pelo método “.dimensions.keys()”, e uma lista das variáveis, através de “.variables.keys()”.
O script a seguir deve carregar um arquivo netCDF (data.nc), ler as variáveis latitude, longitude e uma grandeza definida (“precip”). Posteriormente, serão feitos mapas de distribuição da variável definida – para os mapas, instale os pacotes “matplotlib” e “basemap”:
Os parâmetros “width” e “length” da função “Basemap” referem-se à área do mapa total, independente da área coberta pelos dados do netCDF. Como o arquivo contém dados de vários passos de tempo, foi selecionado somente o primeiro (var[0]). Deve ser gerada uma figura com o mapa da respectiva variável no tempo informado (map.png).
O outro script a seguir cria um arquivo netCDF com tamanho 385 x 538 e valores randômicos inteiros de 0 a 400, para uma variável chamada “varname”:
Ao ser visualizado o mapa, ele deve parecer uma tela de televisão analógica fora de sintonia, conforme a escala de cores definida. Caso queira adicionar ou atualizar dados de um arquivo já existente, basta carregar o arquivo usando a opção “a” (de “append”), em vez de “w” (“write”) ou “r” (“read”).
Os arquivos de entrada, saída e scripts estão disponíveis no Github: Viniroger/netcdf_ex.
É interessante usar o formato de data que os arquivos NetCDF costumam usar, o que pode ser obtido através do método “date2num”. O exemplo a seguir mostra como manipular um dataset usando outro pacote para manipular dados de NetCDF, o xarray, comentado no post sobre vetorização. Nele, é criada uma variável uma data no formato “hours since 0001-01-01 00:00:00.0” para uma data em string (por exemplo, “2016-01-01”) e inserida usando o método “assign_coords”. Também é excluída uma coordenada e uma dimensão que estavam sobrando, chamada “variable”.
def xr_to_nc(ds, filename):
'''
Save xarray to netCDF file
'''
from netCDF4 import date2num
day = filename.split('/')[-1].split('.')[0]
times_units = "hours since 0001-01-01 00:00:00.0"
times_calendar = "gregorian"
date = datetime.strptime(day, "%Y-%m-%d")
time_nc = int(date2num(date, units=times_units,calendar=times_calendar))
# Remove 'strange' coordinate named 'variable'
ds = ds.drop('variable')
ds = ds.squeeze() # remove "dimensions without coordinates"
# Add time coordinate
ds = ds.assign_coords(time=('time', np.array([time_nc])))
ds.to_netcdf(filename)
Imprimindo essa dataset em xarray antes e depois da alteração, fica assim:
<xarray.Dataset>
Dimensions: (latitude: 801, longitude: 1334, variable: 1)
Coordinates:
* longitude (longitude) float32 -74.0 -73.97 -73.94 ... -34.07 -34.04 -34.01
* latitude (latitude) float32 5.0 4.95 4.9 4.85 ... -34.9 -34.95 -35.0
* variable (variable) <U4 'Ceff'
Data variables:
Ceff (variable, latitude, longitude) float64 0.6576 0.6006 ... 0.3081
DARR (latitude, longitude) float64 10.08 9.847 14.71 ... 17.85 18.13
<xarray.Dataset>
Dimensions: (latitude: 801, longitude: 1334, time: 1)
Coordinates:
* longitude (longitude) float32 -74.0 -73.97 -73.94 ... -34.07 -34.04 -34.01
* latitude (latitude) float32 5.0 4.95 4.9 4.85 ... -34.9 -34.95 -35.0
* time (time) int64 17663184
Data variables:
Ceff (latitude, longitude) float64 0.6576 0.6006 ... 0.3002 0.3081
DARR (latitude, longitude) float64 10.08 9.847 14.71 ... 17.85 18.13
Edição de arquivo netCDF
Ainda é possível usar o python para atualizar valores dentro de um arquivo, carregando o dataset como um numpy masked array e acessando-o como “dataset.variables[varname][i,j]”. Veja o exemplo:
def update_nc(self, dayear, lat_i, lon_j, varname, value):
"""
Update NC file with new values
"""
from netCDF4 import Dataset
filename = 'data_%s.nc' %dayear
dataset = Dataset(filename, 'a')
dataset.variables[varname][lat_i,lon_j] = value
dataset.close()
return()
O programa Climate Data Operators (CDO) contém um conjunto de comandos estatísticos e aritméticos úteis para o processamento de dados atmosféricos nos formatos GRIB e NetCDF e foi desenvolvido no Instituto Max Planck de Meteorologia. Veja mais no post sobre Edição de arquivos NetCDF com CDO.
Fontes

Ótimo Artigo, parabéns!
Oi Elton, que bom que gostou. Obrigado pela visita e pelo comentário!
Pq o script pra ler os dados, não retorna os valores negativos?
No arquivo que eu quero ler, alguns dados são valores negativos e para esses dados o script retorna: —
1.3450276128423866e-06
7.879273766775441e-07
1.9876566170751175e-07
—
—
—
Oi Juliano, que estranho, valores pequenos assim podem aparecer quando o python zera o campo. No script não tem nenhuma restrição. Como os arquivos dos exemplos não tem valores, não reparei nesse ponto.