Ao falar de “machine learning” (ou aprendizado de máquina), é comum encontrar tutoriais na internet para resolver problemas de classificação. No entanto, também é possível encontrar padrões em dados históricos de séries temporais, que são os problemas de regressão. Dentre os algoritmos de redes neurais artificiais utilizados com essa finalidade estão o MLP (“Multilayer Perceptron”) e o LSTM (“Long Short Term Memory”). Nesse post, é apresentado um script em python para trabalhar com variáveis explicatórias (séries temporais multivariadas) – não precisa da previsão dessas variáveis, como no caso dos modelos ARIMA.
Diferença entre classificação e regressão
A modelagem preditiva é o problema de desenvolver um modelo usando dados históricos para fazer uma previsão sobre novos dados em que não temos a resposta. Pode ser descrita como o problema matemático de aproximação de uma função de mapeamento (f) de variáveis de entrada (X) para variáveis de saída (y). O trabalho do algoritmo de modelagem é encontrar a melhor função de mapeamento possível, considerando o tempo e os recursos disponíveis.
Fundamentalmente, a classificação é sobre a previsão de uma classe ou categoria, ou seja, a saída é formada de variáveis discretas. Dentre uma das maneiras de estimar a habilidade de um modelo preditivo de classificação, a mais comum é a acurácia: porcentagem de exemplos classificados corretamente de todas as previsões feitas.
Já a regressão é sobre a previsão de uma quantidade, ou seja, a saída é formada de variáveis contínuas. O cálculo mais comumente utilizado para avaliar um modelo preditivo de regressão é a raiz do erro médio quadrático, ou RMSE (root mean squared error).
Tipos de redes neurais artificiais
As redes perceptron contém uma camada de nós de saída, conectados às entradas por conjuntos de pesos. A soma do produtos dos pesos pelas entradas é calculada por cada nó de saída e, se o valor calculado ultrapassar um certo limiar, o neurônio dispara e ajusta a saída para um determinado valor; caso contrário, a saída é ajustada para outro determinado valor. Podem existir mais de uma camada (“layer”) de neurônios, que podem interagir entre si ou não. Veja mais sobre Redes Neurais Artificiais clicando no link.
Nas redes neurais unidirecionais ou pró-alimentadas (“Feed-forward neural network”), os sinais percorram somente um caminho: da entrada para a saída. Não há feedback (loops), isto é, a saída de qualquer camada não afeta a mesma camada. Uma aplicação usando esse tipo de rede é através da função “nnetar()” do pacote forecast do R – veja mais no post Redes neurais de séries temporais no R.
Já as redes neurais recorrentes ou retroalimentadas (RNN, de “recurrent neural network”) podem ter sinais viajando em ambas as direções, introduzindo loops na rede. As computações derivadas da entrada anterior são realimentadas na rede, o que lhes dá um tipo de memória. Seu “estado” está mudando continuamente até atingir um ponto de equilíbrio, permanecendo nele até que o input mude e um novo equilíbrio precise ser encontrado.
O efeito prático disso é a existência de memória de curto prazo na rede. Considerando o aprendizado por treinamento uma espécie de memória de longo prazo, então as redes neurais recorrentes podem criar modelos muito mais complexos, capazes de resolver uma gama maior de problemas.
LSTM
Um exemplo de Rede Neural Recorrente é a arquitetura LSTM (“Long Short Term Memory”), também chamada de “redes de memória de longo prazo”. Seu nome relaciona-se com o fato de que os LSTMs são projetados para evitar o problema de dependência de longo prazo. Afinal, recordar a informação por longos períodos de tempo é praticamente o seu comportamento padrão, algo bem previsível e fácil de aprender.
Em vez de ter uma única camada de rede neural, existem quatro, esquematizados no diagrama a seguir. Nele, cada linha carrega um vetor inteiro (desde a saída de um nó até as entradas dos outros); os círculos cor-de-rosa representam operações pontuais (como a adição de vetores); as caixas amarelas são camadas de rede neural aprendidas; as linhas que se fundem significam concatenação, enquanto que uma linha de bifurcação denota que o seu conteúdo é copiado e enviado para locais diferentes.
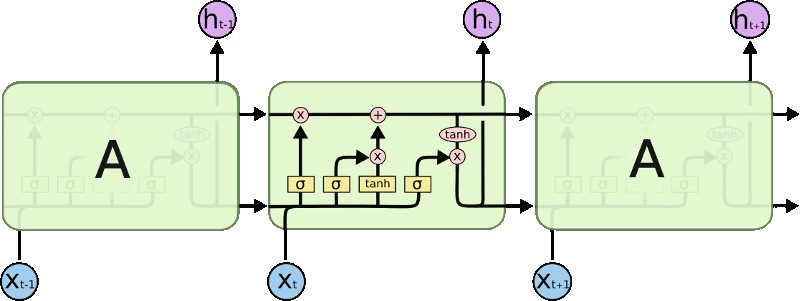
O primeiro passo é decidir qual informação vai sair do estado celular (função sigmoid “forget gate”) e depois qual deve ficar, o que é dividido em duas partes: decidir quais valores devem ser atualizados (função sigmoid “input gate”) e cria um vetor de novos valores candidatos que podem ser adicionados ao estado (função “tanh”). No próximo passo, são combinados estes dois para criar uma atualização para um novo estado celular. Finalmente, é decidido o estado final (função sigmoid “output gate” seguida de uma função “tanh”).
Aplicação em Python
Existem módulos em python que fazem a implementação do LSTM através do módulos tensorflow, theano e keras – muito comuns na área de “data science”, assim como o numpy, o pandas, o scikit-learn e o matplotlib. Eles podem ser instalados usando o pip, conforme segue (via terminal Linux):
sudo apt install python-pip # caso não tenha o instalador pip
pip install --upgrade pip # caso não tenha o instalador pip
sudo pip install tensorflow
sudo pip install theano
sudo pip install keras
O script desenvolvido nessa aplicação (lstm_ex.py) é o resultado de uma mistura desses dois posts do site Machine Learning Mastery:
- Time Series Forecasting with the Long Short-Term Memory Network in Python
- Multivariate Time Series Forecasting with LSTMs in Keras
O primeiro link oferece um tutorial para ajustar um modelo LSTM em uma série de 3 anos de dados mensais de vendas e fazer uma projeção dessa variável. O segundo link também possui um tutorial para aplicar LSTM, mas com dados horários de algumas variáveis meteorológicos. Neste caso, o objetivo é prever a poluição do ar em função de seu próprio histórico e o de outras variáveis – ou seja, um estudo multivariado.
O objetivo aqui é usar o histórico de dados mensais de três variáveis (var_x, var_y e var_z) para gerar a projeção de uma delas (var_y), de modo que os valores de todas as variáveis sejam considerados. Como esses valores possuem uma considerável correlação, é de se esperar que ajudem a melhorar a previsão (e reduzam o valor de RMSE). Uma das variáveis (var_z) possui uma defasagem nos melhores valores de correlação, mas foram utilizados no script sem tratamento prévio. Esta defasagem foi revelada por um gráfico de CCF (correlação cruzada), revelando maiores valores de correlação com um lag/defasagem de 3 a 4 meses – não foi implementado, mas na função “series_to_supervised” pode ser incluído o cálculo para esse lag e usar o tempo “t-3” ou “t-4” em vez de “t-1”.
O script em python está disponível no GitHub/lstm. Nele, primeiramente são carregados o módulos e fixada uma semente (para o numpy e para o tensorflow), de modo a tornar os resultados reprodutíveis quando rodar o script novamente.
Após definição de funções, o primeiro bloco de código lê os arquivos com os dados mensais de entrada, cada série em um arquivo e com o seguinte padrão:
date,value
YYYY-MM-01,FFF.FF
Os valores são concatenados em uma data frame conforme as datas. O segundo bloco deve fazer um gráfico das variáveis em função do tempo.
No terceiro bloco, os dados são normalizados (terem valores entre 0 e 1) e é chamada a função para criar a estrutura de dados para aprendizado supervisionado, além de excluir as colunas que não serão utilizadas (dados em “t” que não são de var_y). Essa função recebe como argumento a sequência de observações como uma lista ou matriz NumPy, o número de observações de atraso como entrada (X), o número de observações como saída (y) e um booleano para indicar se deve ou não descartar linhas com valores NaN, retornando uma DataFrame Pandas com as séries enquadradas para aprendizado supervisionado. Mais informações sobre essa função podem ser vistas no post How to Convert a Time Series to a Supervised Learning Problem in Python.
O quarto bloco divide os dados em parte para treinamento e parte para testes (nesse caso, os últimos 12 meses), além de dividir em dados de entrada (dados do tempo “t-1”) e saída (somente última coluna, dados do tempo “t”). Também deixa tudo no formato [amostras, passo de tempo, padrões].
O próximo bloco tem como objetivo primeiro montar o modelo de redes neurais conforme o número de neurônios (neurons), o número de amostras que serão propagadas pela rede (batch_size) e o número de ciclos/épocas a serem repetidos (epochs). O modelo sequencial é uma pilha linear de camadas – mais informações no link Getting started with the Keras Sequential model. Estão definidas a função de perda (loss) como o erro médio absoluto (MAE, de “Mean Absolute Error”) e o otimizador (optimizer) versão Adam do gradiente estocástico descendente (SGD, de “Stochastic gradient descent”). Além disso, é plotado um gráfico da perda em função do número de épocas, para avaliar o número necessário de ciclos a serem utilizados – veja como interpretar esse gráfico no link How to interpret “loss” and “accuracy” for a machine learning model.
No bloco seguinte, é usado o modelo desenvolvido para fazer uma projeção, “desinverter” os valores normalizados e calcular o RMSE. Em seguida, é feito um gráfico dos valores previstos e dos valores de teste (observados, mas desconsiderados para fazer o modelo).
Rodando o script para algumas combinações de variáveis exógenas, são observados diferentes valores de RMSE (mantendo a mesma semente, definida no início do código). Para isso, deve-se remover a(s) respectiva(s) coluna(s) nas duas linhas com o comando “drop”. A combinação que possuir menor erro pode ser escolhida para fazer previsões operacionalmente. Nesse caso, deve-se não separar em períodos de treino e de teste, de modo que a previsão já comece no final do período de treino.
Os gráficos gerados das séries temporais (series.png), da perda em função do número de épocas (loss.png) e da comparação entre a série de teste original e da gerada pelo modelo treinado (test_and_train.png) estão disponíveis para visualização no GitHub/lstm, assim como o script e os dados de entrada.
Cada vez mais pesquisadores usam redes neurais recorrentes em vez de redes neurais unidirecionais para previsão de séries temporais. O uso de MLP gera bons resultados em muitos conjuntos de dados e ainda é muito implementado.
Fontes
- Matheus Facure – Redes Neurais Recorrentes
- Cross Validated – What’s the difference between feed-forward and recurrent neural networks?
- Machine learning mastery – Difference Between Classification and Regression in Machine Learning
- Nelson, D. – Uso de Redes Neurais Recorrentes para previsão de séries temporais financeiras
- Christopher Olah – Understanding LSTM Networks
- RP’s Blog on Data Science – Recurrent Neural Network (RNN) in Python
- Guo, T. et al – An interpretable lstm neural network for autoregressive exogenous model
- Quora – Is it possible to design a LSTM(RNN) with exogenous variables for forecasting?
- Train a Keras model – fit function
- Slav Ivanov – 37 Reasons why your Neural Network is not working