As deepfakes exigem uma dose extra de ceticismo das pessoa ao se informarem sobre política – seja pela mídia que for. Com o desenvolvimento de algoritmos e da tecnologia de processamento, elas vêm se tornando cada vez melhores e mais populares, além de mais fáceis de se fazer. No entanto, essa técnica pode ajudar na leitura de textos para deficientes visuais e outras atitudes inclusivas.
Deepfake é uma amálgama dos termos “deep learning” (aprendizagem profunda em inglês) e “fake” (falso em inglês, remetendo ao termo “fake news”). É uma técnica de síntese de imagens ou sons humanos baseada em técnicas de inteligência artificial. O “deep learning” é um ramo de aprendizado de máquina (“Machine Learning”) baseado em um conjunto de algoritmos que tentam modelar abstrações de alto nível de dados usando várias camadas de processamento e transformações matemáticas complexas.
Basicamente, o aprendizado de máquina funciona recebendo uma grande quantidade de dados para aprender com essa informação. Isso é chamado de treinamento de modelo. Usando esse modelo, é possível gerar novos resultados. Por exemplo, para clonar uma voz, são usadas horas e horas de gravações.
No entanto, uma técnica publicada em um artigo de janeiro de 2019 permite usar amostras de 5 segundos em um modelo pré-treinado com outras vozes para clonar qualquer voz. O timbre da voz é muito semelhante, e é capaz de sintetizar sons e consoantes que precisam ser inferidos porque não foram ouvidos na amostra de voz original. Isso requer um certo tipo de inteligência e um pouco disso. Então como esse novo sistema funciona?
As três partes da clonagem de voz
O codificador de voz (“encoder speaker”) é uma rede neural que foi treinada em milhares de vozes e tem como objetivo juntar todos esses dados aprendidos em uma representação compactada. Em outras palavras, ele tenta aprender a essência da fala humana com muitos falantes. Essa etapa do treinamento precisa ser realizada apenas uma vez e, depois disso, podem ser usados apenas 5 segundos de dados de fala de alguém (mesmo que não tenha feito parte do treinamento) para depois sintetizar essa voz utilizada como entrada.
O sintetizador que recebe o texto como entrada (“synthesizer”) gera um espectrograma, que é uma representação concisa da voz e entonação de alguém. O espectrograma é um gráfico da frequência em função do tempo, com uma escala de cores para a intensidade – veja mais no post sobre Transformada de Fourier. No caso, ele converte as frequências para a escala Mel (isso porque os humanos não percebem frequências em uma escala linear; somos melhores em detectar diferenças em frequências mais baixas do que em frequências mais altas).
A implementação deste módulo é baseada na técnica Tacotron 2, uma arquitetura de rede neural para síntese de fala diretamente do texto. O sistema é composto por uma rede de predição de recurso sequência a sequência recorrente, que mapeia os encaixes de caracteres em espectrogramas em escala Mel, seguido por um modelo WaveNet modificado que atua como um codificador de voz (“vocoder”) para sintetizar formas de onda de domínio do tempo a partir desses espectrogramas.
A WaveNet é uma rede neural profunda para gerar áudio bruto, criada por pesquisadores da empresa de inteligência artificial DeepMind. É a mesma tecnologia usada para produzir voz para o Google Assistente, a Pesquisa Google e o Google Tradutor. Durante o treinamento, a rede extrai a estrutura subjacente da fala, como quais tons se sucedem e a aparência de uma forma de onda de fala realista. Quando recebe uma entrada de texto, o modelo WaveNet treinado pode gerar as formas de onda de fala correspondentes do zero, uma amostra por vez, com até 24.000 amostras por segundo (24 kHz) e transições contínuas entre os sons individuais.
Implementação em python
O repositório Real-Time Voice Cloning é uma implementação do Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis (SV2TTS), apresentado nesse post, com um vocoder que funciona em tempo real. Uma apresentação dele pode ser visto no vídeo do Two Minute Papres – This AI Clones Your Voice After Listening for 5 Seconds e um exemplo de uso pode ser visto nesse vídeo do autor Corentin Jemine – Real-Time Voice Cloning Toolbox.
Acesse o repositório, baixe o código e descompacte-o. Também será necessário instalar o ffmpeg e o PyTorch. Você pode criar um ambiente virtual no conda, ativá-lo e instalar os pacotes necessários nas versões requiridas (arquivo requirements.txt), conforme segue:
sudo apt install ffmpeg
conda create -n venv python=3.7.9
conda activate venv
conda install pytorch
cd Real-Time-Voice-Cloning-master
conda install conda install --file requirements.txt
Na sequência, baixe os três modelos pré-treinados (speaker encoder, synthesizer, vocoder), salvando os arquivos nos locais indicados no link. Para testar, use o comando “python demo_cli.py” para rodar um script de demonstração – passando ele bem, está tudo OK.
Coletando amostras de áudio
Você pode usar a própria interface para gravar ou usar ao menos quatro amostrar de pelo menos 5 segundos cada. Como os modelos pré-treinados foram feitos com áudios em inglês, esse é o tipo de entrada que eles devem receber. Se quiser em outro idioma, o resultado só vai ficar satisfatório treinando os modelos com arquivos em outros idiomas.
Use arquivos de áudio com um só falante e sem música ou ruídos. Selecione trechos em que a fala é clara – sem vícios de linguagem, longas pausas ou palavras cortadas, por exemplo. Você pode editar o arquivo usando o Audacity, onde basta importar o arquivo, selecionar o trecho e “exportar áudio selecionado como …”. Salve o arquivo no formato FLAC (“Free Lossless Audio Codec”), codec de compressão de áudio sem perda de informação.
Usando a Toolbox
Execute o comando “python demo_toolbox.py” para abrir a interface gráfica da caixa de ferramentas (“toolbox”). Para começar, carregue os arquivos (campo “Use embedding from” e “Browse”) ou grave na hora (mesmo campo, botões “Record” and “Stop”).
Na caixa de texto do canto superior direito, apague o texto padrão e escreva o que deve ser vocalizado. Pontuação e caracteres especiais são ignorados, sendo que o sintetizador espera gerar saídas entre 5 e 12 segundos. Para marcar quebras, escreva uma nova linha – cada linha será tratada separadamente.
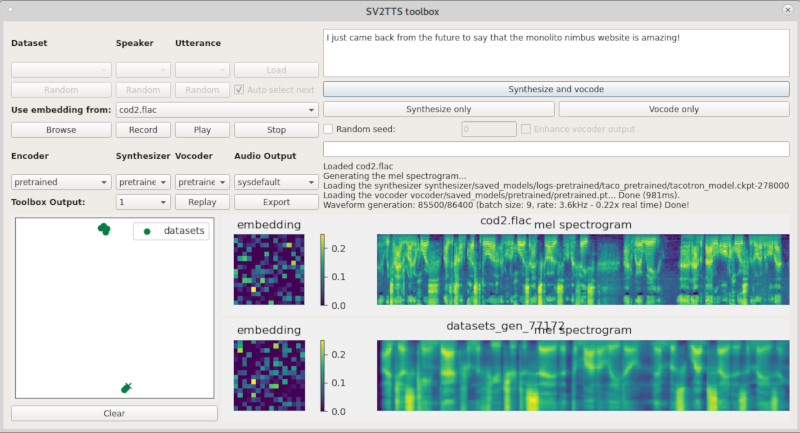
Em seguida, clique em “synthesize and vocode” para gerar o resultado (espectrograma final) e o áudio. Se você tiver pelo menos 2 ou 3 enunciados de um mesmo alto-falante, um cluster deve se formar. Os enunciados sintetizados são da mesma cor do locutor cuja voz foi usada, mas são representados por uma cruz.
O áudio gerado toca automaticamente ao final do processo. Você pode salvar o arquivo clicando em “export” no campo “Audio Output” no formato WAV ou FLAC. Aqui vão alguns exemplos do resultado final com comentários do Doutor Brown (de De Volta Para o Futuro) e dos ex-presidentes dos EUA Barack Obama e Donald Trump sobre esse site:
I just came back from the future to say that the Monolito Nimbus website is amazing!
This is a deepfake audio with Christopher Lloyd voice.
When I first met the Monolito Nimbus website I thought: we can!
This is a deepfake audio with President Obama voice.
Never believe in fake news: visit the Monolito Nimbus website and think critically.
This is a deepfake audio with President Trump voice.

Oi, eu sou Elias, boa tarde.