Em vez de comprar, ter e manter datacenters e servidores físicos, você pode acessar serviços de tecnologia, como capacidade computacional, armazenamento e bancos de dados, conforme a necessidade, usando um provedor de nuvem como a Amazon Web Services (AWS). Isso é computação em nuvem: entrega de recursos de TI sob demanda por meio da Internet com definição de preço de pagamento conforme o uso.
O resumo e tutorial desse post foram baseados nas páginas de Conceitos básicos da AWS. Os três principais tipos de computação em nuvem:
- Infraestrutura como serviço (IaaS) – oferece acesso a recursos de rede, computadores (virtuais ou em hardware dedicado) e espaço de armazenamento de dados (maior controle e flexibilidade)
- Plataforma como serviço (PaaS) – não precisa mais gerenciar a infraestrutura subjacente (geralmente, hardware e sistemas operacionais), mantendo o foco na implantação e no gerenciamento de aplicativos
- Software como serviço (SaaS) – produto completo, executado e gerenciado pelo provedor de serviços para somente ser executado pelo usuário final (um e-mail, por exemplo)
Dentre as ferramentas do desenvolvedor da AWS, estão:
- Console da web – Interface web simples
- Ferramenta de linha de comando – Controle os serviços da AWS pela linha de comando e automatize o gerenciamento de serviços com scripts
- Ambiente de desenvolvimento integrado (Integrated Development Environments – IDE) – Escreva, execute, depure e implante aplicações
- Kit de desenvolvimento de software (Software Development Kit – SDK) – Simplifique a codificação com APIs abstraídas específicas da linguagem para serviços da AWS
- Infraestrutura como código – Defina a infraestrutura de nuvem usando linguagens de programação conhecidas
Uma instância é um servidor virtual na Nuvem AWS. Elas possuem várias combinações de CPU, memória, armazenamento e capacidade de rede – os tipos de instâncias podem ser vistos no link. Os princípios básicos da AWS estão baseados nos cinco pilares:
- Segurança – responsabilidade compartilhada entre a AWS (infraestrutura física, o software e os recursos de rede dos serviços de nuvem) e o cliente (configuração de serviços de nuvem específicos, o software de aplicação e o gerenciamento de dados confidenciais). Todo agente deve ter somente as permissões mínimas necessárias para o desempenho de sua função (incluindo controles de acesso e criptografia).
- Eficiência de performance – servidores são recursos econômicos que podem ser provisionados automaticamente em segundos; deve-se selecionar o serviço (dentro das categorias computação, armazenamento, banco de dados e rede) mais adequado à sua carga de trabalho. Quanto à seleção de serviço na categoria computação, esta pode ser baseada em VM (mais familiar mas pode ser mais cara e exigir mais manutenção), em contêiner (permite habilitar uma divisão mais detalhada da sua carga de trabalho e pode ser dimensionada rapidamente) ou na tecnologia sem servidor (exige a adoção de novas cadeias de ferramentas e processos). Na categoria de armazenamento, deve-se decidir se precisa de um armazenamento de arquivos (como o EFS), de blocos (EBS), de objetos (S3) ou de arquivos mortos (S3 Glacier). Quanto ao banco de dados, pode ser relacional, não-relacional, data warehouse uma solução de indexação e pesquisa de dados. Também de-se decidir o tipo de gerenciamento de computação (EC2, Lightsail ou Elastic Beanstalk), de armazenamento e de banco de dados (RDS ou Aurora). Por fim, deve-se configurar o serviço – memória e CPU, por exemplo, considerando seus requisitos de latência, throughput (taxa de transferência) e IOPS (input/output operations per second). Ainda é possível dimensionar o serviço verticalmente (upgrade para instância maior) e horizontalmente (aumento do número de instâncias subjacentes).
- Confiabilidade – como criar serviços que são resilientes a interrupções de serviços e infraestrutura. Para lidar com a falha quando ela ocorrer, podem ser usadas as seguintes técnicas para limitar seu raio de alcance: isolamento de falhas (fragmentação aleatória, instalações independentes e geograficamente distantes ou implantação de cópias redundantes) e limites (definir cotas de serviço, que são restrições para proteger os serviços contra carga excessiva, como com ataques DDoS e configurações incorretas de software).
- Excelência operacional – melhorar continuamente a capacidade de executar sistemas, criar melhores procedimentos e obter insights. Isso pode ser feito através da automação através de infraestrutura como código (IaC) e monitoramento do estado interno do sistema (coleta de métricas em nível de infraestrutura, aplicação e conta para um estudo analítico e tomada de ação).
- Otimização de custos – alcançar os resultados de negócios e minimizar os custos – por exemplo, usando um modelo contínuo de pagamento conforme o uso (OpEx) em vez de um modelo de compra único (CapEx). Existem diferentes modelos de pagamento: tamanho certo (correspondência entre o provisionamento do serviço e a configuração da carga de trabalho), sem servidor (como o Lambda, somente pago ao ser usado), solicitação de reservas (comprometimento com o pagamento de certo volume de capacidade em troca de um desconto significativo) e instâncias spot (ganhar descontos na execução de cargas de trabalho tolerantes a falhas). Ferramentas da própria AWS podem ser usadas para monitorar e analisar o uso e os custos.
Para realizar os tutoriais a seguir, deve-se criar uma conta na AWS (mesmo para o plano gratuito de 12 meses, precisa colocar o cartão de crédito). Aqui foram selecionados três tutoriais com o objetivo de visualizar uma aplicação web com criação de função sem servidor, uma solução usando código no github e uma aplicação usando Machine Learning. Para todos, quando não for mais utilizar o que foi gerado, é recomendado apagar tudo o que foi desenvolvido, evitando custos extras no futuro.
Como criar uma VM na Amazon AWS EC2
O vídeo incorporado a seguir mostra como criar uma máquina virtual na Amazon desde a criação da conta. Ao realizar o login, deve-se acessar o console da AWS e, no card “Construir uma solução”, escolha “Executar uma máquina virtual (com EC2)”. O EC2 (Elastic Compute Cloud) é o serviço web que disponibiliza capacidade computacional segura e redimensionável na nuvem.
Ao chegar na tela “Etapa 1: Selecione uma Imagem de máquina da Amazon (AMI)”, escolha apenas alguma máquina que esteja marcada como “qualificado para o nível gratuito”. Na “Etapa 2: Escolha um tipo de instância”, somente uma t2.micro que é gratuita (primeiros 12 meses e 750 h/mês de limite). Após revisar e lançar, deve-se criar um par de chaves pública-privada, utilizada para o acesso SSH. Por fim, pode-se executar a instância.
Para acessar essa VM a partir de seu terminal local, veja mais detalhadamente no post Como acessar uma instância na AWS. As horas de utilização da sua nova instância iniciarão imediatamente e serão acumuladas até que você interrompa ou encerre sua instância. Clique em Exibir instâncias para monitorar o status da sua instância, e clique sobre ela com o botão direito para interromper sua atividade (ou mesmo encerrá-la de vez).
Tutorial de Armazenar e recuperar um arquivo com o Amazon S3
O tutorial do link permite aprender como armazenar arquivos (denominados objetos) na nuvem com o Amazon Simple Storage Solution (S3) em escala massiva. Você criará um bucket do Amazon S3, fará upload de um arquivo, e recuperará e excluirá esse arquivo.
Comece acessando o console do S3 e clique em “criar bucket” (contêiner onde os arquivos são armazenados), seguindo com a configuração padrão. Ao voltar para o console, clique no bucket recém-criado e em “carregar” para subir novos arquivos. Para recuperar o objeto (fazer o download do arquivo), basta marcá-lo na caixa de seleção e clicar em “fazer download”. Para apagá-lo, clique em excluir.
Tutorial de Desenvolvedor de soluções completas
Nesse tutorial da AWS Full Stack Developer, o objetivo é criar uma aplicação Web básica e adicionar interatividade com uma API (Application Programming Interface) e um banco de dados. Ou seja, deve-se criar e hospedar um site simples através de uma função sem servidor que será acionada com base em entradas personalizadas em um campo de texto. Os dados do campo de entrada devem ser personalizados e exibidos no site.
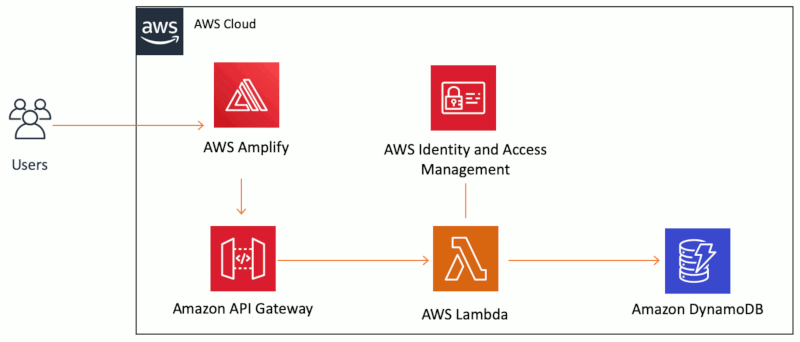
Todo o conteúdo Web estático é hospedado pelo AWS Amplify. Seguindo os passos do tutorial, o código de uma página HTML deve ser comprimido em ZIP e colocado na plataforma, após ter criado o respectivo aplicativo Web. Ele deverá estar disponível em uma URL, algo como “dev.d3oj2ilhps8kp4.amplifyapp.com”.
A funcionalidade dinâmica é implementada usando o AWS Lambda. Nele, as aplicações são divididas em funções individuais, acionadas com base em um evento definido no código (“Trigger do Lambda”). Para criar uma função lambda, entre no Console do AWS Lambda, clique no botão “Create function” e selecione a linguagem de programação/versão desejada (python 3.9, por exemplo). Como o padrão é criar uma função do zero, nesse passo deverá ser incluído o código sugerido pelo tutorial. Siga para a aba “Testar”, digite o nome do teste tipo “Hello World” e use o objeto JSON sugerido no tutorial para testar a função criada.
Na sequência, é usado o Amazon API Gateway para criar e chamar uma API RESTful. REST significa “Representational State Transfer”, ou Transferência de estado representativo, que é um padrão arquitetônico de criação de serviços Web. API significa “application program interface” (Interface de programa de aplicação), que age como intermediário entre o cliente HTML e o back-end sem servidor criados. Assim, a API RESTful é uma API que implementa esse padrão arquitetônico. Além de criar uma nova API, deve-se criar recurso e método novos, além de implementar e validar essa API.
Então será usado o Amazon DynamoDB, um serviço de banco de dados de chave-valor, para criar uma tabela usando o serviço AWS Identity and Access Management (IAM) para conceder aos serviços as permissões necessárias para que eles interajam entre si com segurança. Os dados serão gravados na tabela usando o AWS SDK (Python, JavaScript ou Java) da função do Lambda.
No último módulo do tutorial, o site estático será atualizado para invocar a API REST criada, através da chamada do API Gateway de na página HTML.
Tutorial de Engenheiro de DevOps
Um engenheiro de DevOps é responsável pelo processo de implantação, monitoramento, dimensionamento e tarefas operacionais necessárias ao liberar código. No tutorial da AWS de engenheiro de DevOps (combinação dos termos “desenvolvimento” e “operações”), deve-se criar um ambiente AWS Elastic Beanstalk para rodar o código de um repositório do GitHub, além de implementar automaticamente essa aplicação sempre que o código-fonte for atualizado.
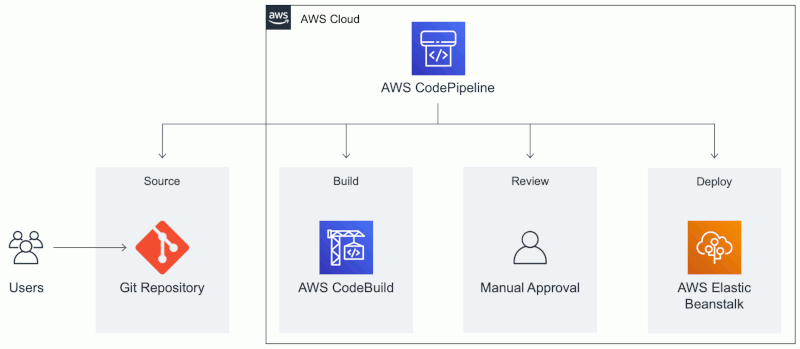
Nesse tutorial, primeiro é configurado um repositório GitHub para o código da aplicação. Então configura-se o AWS CodeBuild para compilar o código-fonte armazenado no GitHub, assim como execução de testes e criação de pacote de software para implantação. Depois, é usado o AWS CodePipeline para configurar o pipeline (modelo de fluxo de trabalho dividido em estágios e respectivas ações) de entrega contínua com os estágios origem, compilação e implantação, adicionando-se um estágio de revisão com aprovação manual antes de implementar. Também é criado um ambiente AWS Elastic Beanstalk para implantar a aplicação – ele provisionará uma ou mais instâncias do Amazon EC2 ao criar um ambiente.
Tutorial de Cientista de Dados
O fluxo de trabalho de Machine Learning (ML) para criar, treinar e implantar modelos em escala é apresentado no tutorial usando Amazon SageMaker, um serviço de machine learning modular, totalmente gerenciado. Nesse caso, busca-se prever se um cliente se inscreverá para um certificado de depósito dado um conjunto de dados de marketing com informações sobre a demografia do cliente, respostas a eventos de marketing e fatores externos.
Acesse o console do SageMaker. No menu lateral, acesse Bloco de anotações -> Instâncias do bloco de anotações e crie uma instância, clicando no botão laranja. Deve-se habilitar o acesso da instância para fazer upload seguro de dados no Amazon S3. Para isso, uma função do IAM deve ser especificada.
Os dados devem ser pré-processados abrindo-se o Jupyter e criando um novo arquivo tipo “conda_python3”. O código está disponível no tutorial. Uma segunda célula também deverá ser criada para criar um bucket do S3 que armazenará os dados – download com a terceira célula. Os dados serão separados em conjuntos de treinamento e de teste.
Para treinar um modelo a partir dos dados, será usado um modelo XGBoost do Amazon SageMaker pré-criado. (Atualização.: no passo 4a, usar sagemaker.inputs.TrainingInput em vez de sagemaker.s3_input). Em seguida, você precisa configurar a sessão do Amazon SageMaker, criar uma instância do modelo XGBoost (um estimador) e definir hiperparâmetros do modelo. O método “xgb.fit” recebendo os dados de treinamento deve gerar o melhor modelo.
Na sequência, o modelo treinado deve ser implementado em um endpoint (ponto de extremidade de comunicação em outro servidor), para então carregar novos dados CSV e executar o modelo para gerar previsões. Para tanto, são usados os métodos “xgb.deploy” e “xgb_predictor”. (Atualização: remova a seguinte linha: xgb_predictor.content_type = ‘text/csv’)
A última etapa envolve avaliar a performance e a precisão do modelo de ML. Assim, são comparados os valores reais vs. previstos em uma tabela chamada “matriz de confusão”. Para finalizar, é recomendável encerrar os recursos que não estão em uso, para evitar cobranças, ou seja, excluir o endpoint do Amazon SageMaker e os objetos no bucket do S3.



