O processador também é conhecido como CPU (Central Processing Unit, ou unidade central de processamento). Ele que é a parte de um sistema computacional que realiza as instruções de um programa de computador, para executar a aritmética básica, lógica, e a entrada e saída de dados. Eles são caracterizados por seu clock (indicam a velocidade de processamento em ciclos por segundo, geralmente apresentado em GHz), por sua arquitetura (32 ou 64 bits a cada ciclo de processamento) e por sua memória cache (de acesso muito mais rápido que a RAM).
Um processo é uma instância de um programa em execução, com entrada e saída de dados e um estado (executando, bloqueado, pronto). Um programa (visão do programador/usuário) pode ter várias instâncias, mas um processo (visão do sistema operacional) é único. Uma CPU só pode executar um processo de cada vez. Um processador pode possuir vários núcleos (ou cores) no interior de um chip, permitindo o processamento simultâneo. Quanto mais threads usar em um mesmo núcleo, mais o processamento será compartilhado.
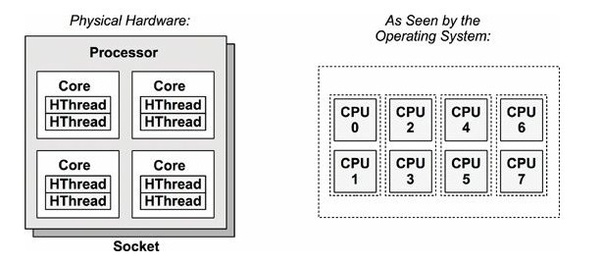
Um core pode ter mais de uma thread (do inglês linha), que é uma linha de execução de um processamento. Cada thread possui um espaço de endereço e múltiplas linhas de controle, sendo que seu conjunto compõe as linhas de execução de um processo. As threads compartilham um mesmo espaço de endereço, pois compõe o processo, mas diferentes pilhas de execução, contadores de programa, registradores e estado.
Threads podem ser úteis em aplicações com muitas atividades ao mesmo tempo, principalmente quando existem tarefas que exigem muito de processamento (tempo de execução mais rápido) e muito acesso a disco (mais lento) se sobrepondo. São também mais rápidas de criar e destruir do que os processos e úteis no paralelismo com múltiplas CPUs (cada thread pode ser colocada em um core).
Como cada thread pode ter acesso a qualquer endereço de memória dentro do espaço de endereçamento do processo, uma thread pode ler/escrever/apagar a pilha ou as variáveis globais de outra thread. Assim, devem ser feitos mecanismos de sincronização para que as threads não compitam.
Paralelização no python
As bibliotecas NumPy, SciPy, pandas e outras consideram o código vetorizado e permitem otimizar o desempenho de execuções. No entanto, um programa pode ficar até mais lento ao usar várias threads.
A expectativa é que, em uma máquina com vários núcleos, um código com vários segmentos faça uso desses núcleos extras e, assim, aumente o desempenho geral. Infelizmente, as partes internas do interpretador Python principal (CPython) negam a possibilidade de verdadeiro multithreading devido a um processo conhecido como Global Interpreter Lock (GIL).
O GIL é necessário porque o interpretador Python não é seguro para threads. Isso significa que há um bloqueio imposto globalmente ao tentar acessar com segurança objetos Python de dentro de threads. A qualquer momento, apenas uma única thread pode adquirir um bloqueio para um objeto Python ou API C. O interpretador irá readquirir esse bloqueio para cada 100 bytecodes de instruções Python e ao redor (potencialmente) de operações de E/S de bloqueio. Devido a esse bloqueio, o código vinculado à CPU não terá ganho de desempenho ao usar a biblioteca Threading, mas provavelmente aumentará o desempenho se a biblioteca Multiprocessing for usada.
Como o interpretador do Python não suporta a verdadeira execução multi-core via multithreading, onde a biblioteca Threading pode ser vantajosamente aplicada? Existem programas em que alguns processos são mais lentos do que o acesso à memória local ou ao cache da CPU, como acesso à rede (network-bound) ou ao disco (I/O-bound). Nesses casos, o interpretador Python ficaria esperando o resultado de uma chamada de função que está manipulando dados dessas fontes. Caso fosse gerado um encadeamento de acessos simultâneos a vários itens, haveria um ganho de tempo.
Já em aplicações numericamente intensivas, como soluções de álgebra linear em grande escala ou sorteios estatísticos aleatórios, o limitante é a CPU. Nesses casos, para realmente fazer uso dos núcleos extras presentes em quase todos os processadores de consumo modernos, deve-se usar o Multiprocessing. A sintaxe é muito parecida, mas seu funcionamento é bem diferente.
A biblioteca de multiprocessamento gera vários processos do sistema operacional para cada tarefa paralela. Isso evita o GIL, dando a cada processo seu próprio interpretador Python. Portanto, cada processo pode ser alimentado para um núcleo de processador separado para serem reagrupados no final, quando todos os processos forem concluídos. Deve-se atentar para uma eventual sobrecarga de E/S, caso os dados não sejam restritos a cada processo.
Multiprocessamento em python
O pacote “multiprocessing” suporta processos de geração usando uma API semelhante ao módulo de segmentação. Ele oferece simultaneidade local e remota, efetivamente ultrapassando o bloqueio global de intérpretes usando subprocessos em vez de threads.
O objeto “pool”, que oferece um meio conveniente de paralelizar a execução de uma função entre vários valores de entrada, distribui os dados de entrada entre processos (paralelismo de dados). O parâmetro “processes” é o número de processos de trabalho a serem usados; se for “None”, então é usado o número retornado por “os.cpu_count()”.
O método “map” divide o iterável em vários pedaços que ele envia ao “pool” de processos como tarefas separadas. O tamanho (aproximado) desses pedaços (“chunks”) pode ser especificado configurando “chunksize” como um número inteiro positivo. Os blocos são executados em ordem.
Para mapear tarefas para processos, deve-se considerar o número de argumentos, simultaneidade, bloqueio e pedido. O método “map” vai esperar por terminar o processamento de todos os pedaços, ou seja, ele é “bloqueador”. Já o método “map_async” executa os blocos assincronamente, bloqueando somente quando o método “wait” é chamado. Pode-se definir um loop infinito que verifica quando o pool responde dizendo que está tudo pronto através do método “result”.
Caso precise entrar com número de argumentos maior do que um, desde a versão 3.3 do python existem os métodos “starmap” e “starmap_async”. Neles, os argumentos devem ser iteráveis, que são descompactados para serem usados como argumentos.
Multithread em python
No python, o pacote threading permite transformar uma classe em thread através de duas modificações: a classe em questão deve estender à classe Thread desse pacote e deve-se implementar o método run(), que será chamado quando a thread iniciar.
O conteúdo do método run será executado em uma thread separada sempre que o método start, definido na classe Thread e herdado pela classe utilizada, for chamado. A partir do momento que as threads foram iniciadas, o sistema operacional vai escaloná-las. Assim, as threads podem ser executadas em ordens diferentes para diferentes rodadas.
A princípio, as threads efetuam processamentos paralelos distintos e sem ligação entre si. No final do processamento das threads, é possível unir os resultados delas através do método “join”, o que é conhecido como sincronização. Outra forma de sincronização é usada quando há necessidade de se acessar variáveis cujos valores são compartilhados por várias threads rodando simultaneamente, através das locks (threading.Lock) ou semáforos (threading.Semaphore).
Aplicações
O post Exemplos de paralelização em python contém scripts com diferentes aplicações de multiprocessing e de multithread, com uma aplicação completa para leitura de um dataframe linha por linha. O post Paralelização em R e bash contem os principais comandos usados para processamento em paralelo nas duas linguagens.
Fontes



3 comments