A EfficientNet é uma família de arquiteturas de redes neurais convolucionais que foram projetadas para serem altamente eficientes em termos de consumo de recursos computacionais enquanto mantêm ou melhoram o desempenho em tarefas de visão computacional. Ela foi proposta por Mingxing Tan e Quoc V. Le em um artigo intitulado “EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks“, publicado em 2019. Reveja alguns conceitos báscios para seu entendimento e um exemplo de arquitetura.
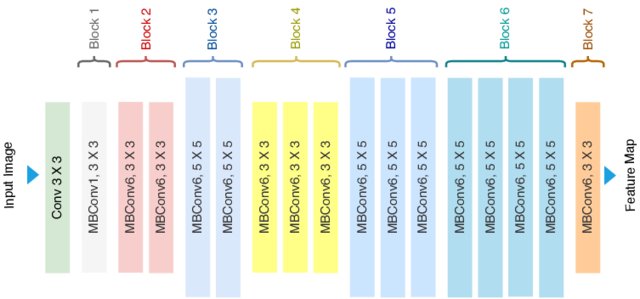
A primeira versão dessa arquitetura, a EfficientNet-B0, teve um processo inovador de criação. Em vez de ser projetada manualmente por engenheiros de machine learning, ela foi desenvolvida usando um método chamado de “neural architecture search” (NAS) ou busca de arquitetura neural. Tomando B0 como modelo básico, os autores desenvolveram uma família completa de EfficientNets de B1 a B7 (setembro/2021) que alcançou precisão de última geração no ImageNet e ao mesmo tempo foi muito eficiente em relação aos seus concorrentes.
Conceitos básicos
As redes neurais concoluvionais (CNNs) são um tipo de arquitetura de rede neural especialmente eficazes para tarefas relacionadas a visão computacional, como reconhecimento de imagem e processamento de vídeo. Elas são capazes de aprender padrões complexos em dados de entrada, como imagens, através de camadas de convolução que aplicam filtros para detectar características específicas.
A convolução é uma operação matemática que combina duas funções para produzir uma terceira. Na convolução de imagens, é uma técnica para modificar ou transformar uma imagem usando um pequeno filtro (também chamado de kernel ou máscara) para produzir uma nova imagem. Esse filtro, geralmente uma matriz 3×3 ou 5×5, é deslizado sobre a imagem de entrada. Cada elemento no filtro possui um valor numérico. Em cada posição do filtro, os valores correspondentes na imagem de entrada são multiplicados pelos valores no filtro. Estes produtos são então somados para obter um único valor. O filtro é deslizado sobre toda a imagem, uma posição de cada vez. Dependendo do método de convolução usado (por exemplo, convolução completa ou convolução com preenchimento), a posição inicial, o passo (stride) e o preenchimento podem variar.
O resultado das somas é mapeado para formar uma nova imagem, chamada de mapa de características/recursos (feature map) semânticos (semântica é o estudo do significado, incide sobre a relação entre significantes, tais como palavras, frases, sinais e símbolos, e o que eles representam). Os mapas de recursos são representações intermediárias das características encontradas nos dados de entrada. No contexto de uma CNN, esses mapas capturam diferentes níveis de abstração, desde padrões simples (baixo nível), como bordas e texturas, até características mais complexas, como formas e padrões.
Convolução separável
Uma convolução padrão, que refere-se à convolução tradicional em que um único filtro (ou kernel) é aplicado a todos os canais de entrada. Neste caso, cada canal na entrada é convoluído com o mesmo filtro, produzindo um canal na saída.
Já a convolução separável (separable convolution em inglês) é uma técnica que divide a convolução padrão em duas etapas: convolução em profundidade (depthwise convolution) e convolução ponto a ponto (pointwise convolution). Essa abordagem é frequentemente usada para reduzir o número total de operações em uma rede neural, tornando-a mais eficiente computacionalmente.
- Convolução em Profundidade (Depthwise Convolution): basicamente aplica-se a operação de convolução separadamente a cada canal que compõe a imagem. Cada canal de cor (por exemplo, vermelho, verde e azul em uma imagem RGB) é tratado de forma independente, usando um filtro específico para aquele canal, criando um mapa de características separado para cada canal. Em outras palavras, para uma entrada com C canais e D filtros de convolução 3×3, por exemplo, teríamos C×D operações de convolução 3×3. Isso difere da convolução padrão, onde todos os canais da entrada são convoluídos com todos os filtros, resultando em C×D×D operações para uma convolução 3×3.
- Convolução Ponto a Ponto (Pointwise Convolution): Após a convolução em profundidade, uma convolução ponto a ponto é aplicada. Nessa etapa, é usada uma convolução 1×1, onde cada canal de saída é formado pela combinação linear dos canais de entrada. Isso ajuda a criar relações não lineares entre os canais de entrada. A convolução ponto a ponto ajuda a aumentar a dimensionalidade dos dados, permitindo que eles sejam mapeados para espaços de características mais complexos.
A convolução 3×3 separável tem menos parâmetros o que uma convolução 5×5 separável, o que a torna mais eficiente em termos de armazenamento e computação. Filtros 3×3 são eficazes para capturar padrões locais em uma imagem ou em dados espaciais, pois têm um campo receptivo relativamente pequeno. Pode-se empilhar mais camadas 3×3 para aumentar a profundidade da rede, permitindo que a rede aprenda representações mais complexas e hierárquicas.
Já o filtro de uma convolução 5×5 é melhor para capturar padrões globais em comparação com um filtro 3×3. Eles têm um campo receptivo maior, permitindo que a rede aprenda características que se estendem por uma área maior dos dados. Em alguns casos, uma convolução 5×5 separável pode substituir duas ou mais camadas de convolução 3×3 separável para alcançar o mesmo campo receptivo, economizando recursos computacionais.
EfficientNet
A EfficientNet utiliza um método chamado de escalabilidade composta (“compound scaling”). Esse método escala simultaneamente a profundidade, largura e resolução da rede para encontrar a melhor combinação de todas essas dimensões:
- Profundidade (d): A profundidade de uma rede neural se refere ao número de camadas que a rede possui. Redes mais profundas podem aprender representações mais complexas, mas também são mais computacionalmente intensivas.
- Largura (w): A largura de uma rede se refere ao número de canais em cada camada (ou seja, o número de características ou filtros em cada camada convolucional). Redes mais largas podem capturar mais informações em cada camada, mas também aumentam o custo computacional.
- Resolução de entrada (r): A resolução de entrada é o tamanho das imagens que a rede recebe como entrada. Reduzir a resolução de entrada economiza recursos computacionais, mas pode levar à perda de detalhes nas imagens de entrada.
No “compound scaling” do EfficientNet, Em vez de aumentar todas as dimensões de forma igual (por exemplo, duplicar a profundidade, largura e resolução), ele utiliza uma fórmula de escala composta que ajusta essas dimensões de forma não uniforme:
\(d = \alpha^{\phi}\\
w = \beta^{\phi}\\
r = \gamma^{\phi}
\)
onde α, β, γ são hiperparâmetros que controlam quanto cada dimensão é escalada, e ϕ é um coeficiente de escala composta que controla o equilíbrio entre as dimensões. A ideia é encontrar os valores ótimos para α, β, e γ que maximizam a precisão da rede para uma carga computacional fixa.
A carga computacional é uma métrica específica do modelo e do hardware utilizado. Ela refere-se à quantidade de trabalho computacional necessária para treinar ou executar um modelo de rede neural, estando relacionada ao número total de operações (como adições e multiplicações) que o modelo precisa realizar durante o treinamento ou inferência. Em um contexto de treinamento, a carga computacional é afetada pelo tamanho do conjunto de dados, número de parâmetros (pesos e vieses do modelo), profundidade da rede, operações por camada e pelo número de épocas (iterações completas pelo conjunto de dados)
MBConv
A EfficientNet utiliza blocos de construção chamados de MBConv (Mobile Inverted Bottleneck Convolution), que são inspirados na arquitetura MobileNet. A MobileNet é uma família de arquiteturas de rede neural projetadas especificamente para dispositivos móveis e outras plataformas com recursos computacionais limitados. A convolução separável em profundidade divide uma operação de convolução padrão em duas etapas: uma convolução 1×1 para projetar os dados em um espaço de características de menor dimensão, seguida por uma convolução separável em cada canal (convolução profunda). Isso reduz drasticamente o número de operações necessárias, tornando a arquitetura adequada para dispositivos com recursos limitados.

O bloco MBConv é uma versão modificada do bloco Inverted Residual introduzido pelo MobileNetV2. De modo geral, ele consiste em três operações principais de convolução e algumas outras etapas, conforme segue:
- Convolução 1×1: Esta camada reduz a dimensionalidade dos dados, projetando-os em um espaço de características de menor dimensão. Isso ajuda a economizar recursos computacionais.
- Swish Activation
- Batch Normalization (BN): A normalização em lotes é uma técnica usada para normalizar as ativações em uma camada, ajudando a estabilizar e acelerar o treinamento de redes neurais.
- Convolução 3×3 (ou 5×5): Em seguida, uma convolução 3×3 é aplicada para capturar padrões complexos nos dados, que pode ser padrão ou separável (explicação dessa diferença mais à frente). A convolução 3×3 é a operação mais intensiva em termos computacionais, então, ao primeiro reduzir a dimensionalidade com a convolução 1×1, a carga computacional é significativamente reduzida. O tamanho do kernel pode ser 3×3, 5×5 ou outro, conforme as necessidades específicas da arquitetura e da tarefa em questão.
- Swish Activation
- Batch Normalization
- Módulo Squeeze and Excitation (SE): O módulo Squeeze and Excitation é uma técnica que permite que a rede aprenda a ponderar a importância de diferentes canais de entrada de acordo com o contexto da tarefa, melhorando a representação aprendida pela rede.
- Convolução 1×1 linear: Finalmente, outra convolução 1×1 é aplicada para aumentar a dimensionalidade dos dados de saída, preparando-os para a próxima camada. Esta camada é linear, o que significa que não introduz não-linearidades, ajudando na estabilidade do treinamento.
- Batch Normalization
- Dropout: usada para regularização, ajudando a evitar overfitting durante o treinamento.
- Soma com a Entrada Original: No final do bloco MBConv, a saída do bloco (após todas as operações) é somada com a entrada original do bloco. Esse tipo de conexão, chamado de conexão de atalho ou residual, ajuda no fluxo do gradiente durante a retropropagação, facilitando o treinamento de redes profundas e ajudando a evitar problemas como o desaparecimento do gradiente. Além disso, a conexão de atalho ajuda a preservar informações úteis e detalhes da entrada original, o que pode ser particularmente importante em tarefas de visão computacional.
Existem diferentes versões do MBConv conforme a quantidade de camadas convolucionais separáveis que compõem o bloco. O que foi descrito acima é um MBConv1, pois a camada convolucional separável é aplicada dentro do bloco MBConv uma única vez. Uma “MBConv6”, por exemplo, é aplicada seis vezes dentro do bloco MBConv. Ou seja, há seis camadas convolucionais separáveis empilhadas para capturar padrões complexos e ricos nos dados.
Função de ativação Swish
Em redes neurais artificiais, após a aplicação de uma operação de transformação linear (como uma multiplicação de matriz na camada oculta), uma função de ativação é aplicada para introduzir não-linearidade nas redes. Sem uma função de ativação, a rede seria essencialmente equivalente a uma única camada de transformação linear, não importando quantas camadas você adicionasse. Funções de ativação introduzem complexidade e flexibilidade nas representações aprendidas pela rede, permitindo que a rede aprenda padrões não-lineares nos dados.
A ReLU (Rectified Linear Unit) é uma função de ativação popular que define a saída como zero para valores de entrada negativos e deixa os valores positivos inalterados. A função ReLU é definida como: f(x)=max(0,x). Ela é computacionalmente eficiente e ajuda a mitigar o problema de desaparecimento de gradientes. No entanto, tem uma desvantagem: para entradas negativas, a saída é sempre zero, o que pode levar a problemas conhecidos como “dying ReLU”, onde certos neurônios param de aprender completamente porque sempre produzem zero.
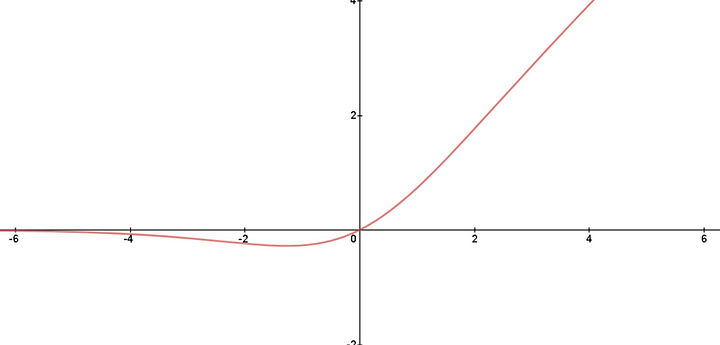
Swish é uma função de ativação que é uma variação da função de ativação ReLU (Rectified Linear Unit). Ela foi proposta como uma alternativa ao ReLU para fornecer um melhor desempenho em algumas tarefas, especialmente em arquiteturas profundas. Ela é definida como:
\(f(x)=x\cdot σ(βx)\)onde onde σ é a função sigmoide σ(z)=1/(1+e−z) e β é um parâmetro que controla a suavidade da função. A vantagem da Swish sobre a ReLU é que ela é diferenciável em todos os pontos, ao contrário da ReLU, que não é diferenciável em zero. Funções de ativação diferenciáveis são importantes para métodos de otimização que dependem do gradiente, como o algoritmo de retropropagação usado para treinar redes neurais.
Fontes
- Ahmed, Tashin & Sabab, Noor. (2020). Classification and understanding of cloud structures via satellite images with EfficientUNet. 10.1002/essoar.10507423.1.
- Li, X.; Qiu, B.; Cao, G.; Wu, C.; Zhang, L. (2022). A Novel Method for Ground-Based Cloud Image Classification Using Transformer. Remote Sens. 2022, 14, 3978. https://doi.org/10.3390/rs14163978

2 comments