A transcrição de áudio (o ato de converter um arquivo de som em texto) pode ser bastante trabalhosa. No entanto, graças ao aprendizado de máquina, já existem vários algoritmos automáticos que rendem boas transcrições, restando apenas uma verificação no final do trabalho.
Boa parte dos aplicativos e ferramentas existentes com esse intuito tem o foco em gravar um áudio curto para conversão e uso naquele momento. No entanto, caso possua um arquivo de áudio com vários minutos, pode ser interessante o uso de APIs e um pouco de programação para tirar melhor uso dessas ferramentas.
Basicamente, os algoritmos usando aprendizado de máquina precisam aprender com exemplos, ou seja, comparar palavras faladas já relacionadas às escritas e ter uma flexibilidade para identificar essa correlação em outros áudios. Assim, esse treinamento deve ser feito para cada idioma. Quanto mais termos e sotaques estiverem presentes, melhor será o aprendizado.
O Python possui a SpeechRecognition, uma biblioteca para realização de reconhecimento de fala, com suporte para diversos engines e APIs, online e offline (sem acessar servidor remoto). APIs da Microsoft, Google e IBM necessitam de acesso registrado nos modelos treinados na nuvem.
O serviço IBM Watson™ Speech to Text transcreve áudio para texto. Para seu uso, primeiro é preciso acessar a página do Speech to text e criar uma conta. Na Lista de recursos, acesse a página de serviços para copiar as credenciais (valores de ‘API key’ e de ‘URL’).
O Speech to Text também usa curl para chamar os métodos da interface HTTP do serviço, o que permite usar comando direto no terminal ou bash script. Você pode seguir o tutorial do link que possui um arquivo de teste. O comando com parâmetros é basicamente o seguinte:
curl -X POST -u "apikey:<SUA API KEY>" --header "Content-Type: audio/flac" --data-binary @<PATH E NOME DO ARQUIVO FLAC> "<URL>"
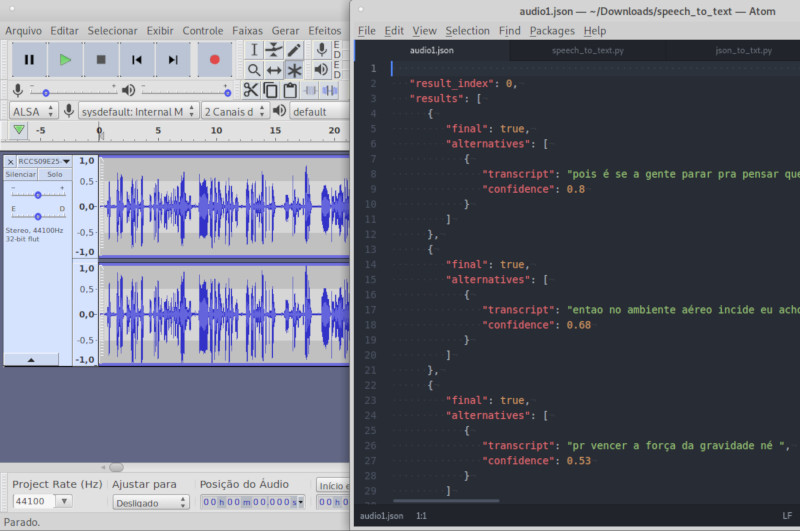
O resultado é impresso na tela no formato JSON, com os campos “confidence” (quanto mais perto de 1, maior a confiança na transcrição) e “transcript” (texto transcrito). Para transcrição de texto em português do Brasil, inclua “?model=pt-BR_BroadbandModel” no final da URL.
Caso vá editar um arquivo muito grande (maior do que 100 MB), tente separar em pedaços menores, selecionando trechos semelhantes com poucos minutos – por exemplo, com o mesmo falante em cada um. No Audacity, exportei usando nível 8 (o melhor) e profundidade de 16 bits. Quanto maior a taxa de amostragem, melhor o resultado – aconselha-se um mínimo de 16 kHz. Veja mais sobre os formatos de opções de áudio aceitáveis/aconselhados no tópico Formatos de áudio da IBM.
O script a seguir em python (speech_to_text.py) monta o comando cURL para ser executado na linha de comando do Linux, ajudando a ler a chave e parte da URL do arquivo JSON de credenciais. Também facilita a geração do nome dos arquivos de entrada (áudio) e de saída (JSON).
#!/usr/bin/env python3.7.9
# -*- Coding: UTF-8 -*-
import json
import os
# Input/Output information
num = '1'
file_in = 'audio{0}.flac'.format(num)
file_out = 'audio{0}.json'.format(num)
# Get API key and URL from JSON
f = open('ibm_credentials.json')
json_dict = json.load(f)
API_KEY = json_dict['apikey']
URL = json_dict['url']+'/v1/recognize?model=pt-BR_BroadbandModel'
# Execute cURL command to get information
# and save output to text file
cmd = 'curl -X POST -u "apikey:{0}"\
--header "Content-Type: audio/flac"\
--data-binary @{1} "{2}" > {3}'.format(API_KEY, file_in, URL, file_out)
#print(cmd)
result = os.system(cmd)
Cada espaço sem som é entendido como um delimitador de trechos, sendo que cada um destes retorna como um “result” diferente no arquivo JSON de saída. O script a seguir (json_to_txt.py) lê o arquivo JSON gerado para extrair os campos com as transcrições e imprimir tudo em um só arquivo de texto.
#!/usr/bin/env python3.7.9
# -*- Coding: UTF-8 -*-
import json
# Input/Output information
num = '1'
file_in = 'audio{0}.json'.format(num)
file_out = 'audio{0}.txt'.format(num)
# Get JSON transcript
f = open(file_in)
json_dict = json.load(f)
# Save all transcripts to one list
lst = []
for result in json_dict['results']:
lst.append(result['alternatives'][0]['transcript'])
# Save list to TXT file
with open(file_out, 'w') as f:
for item in lst:
f.write('%s\n' % item)
Salvando os arquivos de áudio ordenadamente, basta mudar a variável “num” para mudar de arquivo. Isso pode ser automatizado dentro de um loop, no caso de muitos arquivos. Para juntar todos os arquivos de texto em um só, basta usar o comando “cat audio*.txt > transcript.txt” no terminal, redirecionando a saída de todos os textos ordenados para o arquivo TXT de saída.
ATUALIZAÇÃO (2024)
Uma nova forma de fazer transcrição de áudio para texto, e usando seu próprio computador, é através da biblioteca Whisper, da OpenAI, no python. Para utilizá-la, crie um ambiente virtual e instale os pacotes necessários:
conda create -n transc
conda activate transc
pip install openai-whisper
Dentre os pacotes instalados, está o pytorch. Depois, use o seguinte script, bastando apenas alterar o nome do arquivo. Redirecione a saída do script para um arquivo de texto ou altere o código para salvar o resultado em um arquivo.
import whisper
# Carregar o modelo
model = whisper.load_model("medium") # Ou "base", "small", "large" dependendo do desempenho desejado
# Transcrever um arquivo de áudio
result = model.transcribe("nc.mp3", language="pt")
# Exibir o texto transcrito
print(result["text"])