O MySQL é um sistema de gerenciamento de banco de dados (SGBD), que utiliza a linguagem SQL (Linguagem de Consulta Estruturada, do inglês Structured Query Language) como interface e atualmente é um dos bancos de dados mais populares do mundo. O sucesso do MySQL deve-se em grande medida à fácil integração com o PHP incluído, quase que obrigatoriamente, nos pacotes de hospedagem de sites da Internet oferecidos atualmente.

Bancos de dados são coleções organizadas de informações (dados) que se relacionam de forma a criar um sentido e dar mais eficiência durante uma pesquisa ou estudo. O banco de dados relacional trabalha com tabelas e o orientado a objetos trabalha com classes.
Bancos de dados SQL em geral são transacionais, ou seja, permitem executar uma sequência de operações como um bloco indivisível (ou é executado como um todo, ou tudo é desfeito) de forma a garantir a integridade dos dados ao final da transação em um ambiente com acesso concorrente. Uma transação em andamento não pode ser acessada por outras transações de modo a evitar leitura de um estado inconsistente, uma “sujeira”.

O MySQL permite alguns mecanismos de armazenamento para suas tabelas, identificado pelo campo “TYPE” (ou “ENGINE) durante sua criação. O MyISAM (formato padrão) oferece travamento por tabela, ou seja, quando um dado está sendo escrito em uma tabela, ela toda será trancada e outras escritas deverão esperar. Já o InnoDB é um tipo de tabela transacional que oferece travamento por coluna. Em termos de performance, o MyISAM é melhor para tabelas fixas, como uma tabela de cidades e localizações, enquanto que o InnoDB é mais rápido para tabelas em constantes mudanças. Tabelas HEAP são armazenadas em memória e por isto são extramente rápidas (boas quando são consultadas com muita frequência), por outro lado o seu conteúdo é volátil.
Instalação e configuração
Para instalar MySQL, use o repositório (“sudo apt-get install mysql-server”, vai pedir para registrar senha de root). Depois, acesse o programa para realizar algumas configurações:
$ mysql -u root -pSENHANo modo “linha de comando”, deverá ser utilizada a linguagem SQL para os trabalhos, sempre finalizando os comandos com ponto e vírgula (;). Deve-se cria o usuário, com acesso permitido somente de localhost nesse caso, e a senha de acesso. Em seguida, defina as políticas de acesso do usuário (nesse exemplo, o usuário tem permissão para acessar tudo e somente a partir de localhost; se usar % em vez de localhost, o usuário tem permissão para acessar tudo a partir de qualquer host). Os comandos para isso são:
> CREATE USER 'locator'@'localhost' IDENTIFIED BY 'senha';
> GRANT ALL PRIVILEGES ON *.* TO 'locator'@'localhost' IDENTIFIED BY 'senha' WITH GRANT OPTION;O ‘localhost’ pode ser substituído pelo IP, tratando-se de acesso remoto autorizado para esse número. Veja mais alguns comandos:
> SELECT user FROM mysql.user; /* Exibe todos os usuários */
> SHOW GRANTS; /* Exibe as permissões que o usuário atual possui */
> SHOW GRANTS FOR usuario@host; /* Exibe as permissões que o usuário possui */
> SET PASSWORD FOR 'root'@'localhost' = PASSWORD('senha'); /* Trocar a senha */
Para configurar MySQL para acesso externo, edite o arquivo /etc/mysql/my.cnf como superusuário e comente a linha “bind-address = 127.0.0.1”. Em seguida, reinicie o MySQL:
$ sudo /etc/init.d/mysql restartEstrutura e Linguagem SQL
A estrutura envolve as bases de dados (databases), que por sua vez contém as tabelas (tables). Cada tabela possui linhas e colunas, onde o encontro delas geram os campos (fields). Cada conjunto de campos é identificado por uma chave primária (primary key), cujos valores nunca se repetem e podem ser usados como identificadores dos campos (ID).
O MySQL para isso suporta diferentes tipos de dados (data types): texto, numérico e temporal. Cada um possui variações conforme o número de bytes reservados para cada célula. Dentre os principais, estão:
- inteiro: INT
- real: FLOAT ou DOUBLE
- texto não-binário: CHAR ou VARCHAR
- texto binário: BINARY
- data: TIMESTAMP (formato ano/mês/dia horma:minuto:segundo)
- boolenano: BOOLEAN
Deve-se informar o tamanho do campo (em caracteres) entre parênteses para “varchar” e “int”. No caso de “float”, deve-se informar a precisão (número total de dígitos permitidos tanto à esquerda quanto à direita do ponto decimal) e escala (número de dígitos permitidos à direita do ponto decimal) com o formato “float(precisão,escala)”. Com relação à “timestamp”, os valores permitidos vão desde o ano de 1970 até 2037.
Para criar uma tabela dentro de um banco de dados, é utilizada a sintaxe básica (após selecionada a base de dados):
CREATE TABLE nome_tabela (nome_campo_1 tipo_1,nome_campo_2 tipo_2, ... nome_campo_n tipo_n, PRIMARY KEY (campo_x));Existem algumas opções, como a AUTO_INCREMENT, onde a cada registro, é somado 1 (um) em seu valor (muito utilizado para identificar as primary keys, e também a opção NOT NULL, que define que um determinado campo seja de preenchimento obrigatório. Veja esse exemplo:
> CREATE TABLE clientes(
codigo int(4) AUTO_INCREMENT,
nome varchar(30) NOT NULL,
email varchar(50),
data_nascimento date,
PRIMARY KEY (codigo)
);Caso queira inserir um novo cliente (nova linha), use o comando:
> INSERT into clientes VALUES ('','Fulano','fulano@email.com.br','1988-08-08');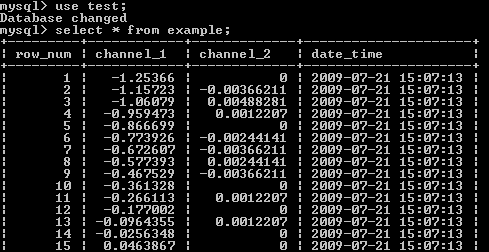
Usando a linha de comando do MySQL, temos alguns comandos muito utilizados (os comentários são dados entre barra e asterisco conforme segue):
> show databases; /* exibir as bases de dados */
> USE nome_da_database; /* usar a base de dados */
> SHOW tables; /* mostrar as tabelas */
> SELECT * FROM nome_da_tabela ORDER BY id DESC limit 10; /* selecionar as 10 últimas linhas */
> SELECT count(1) FROM nome_da_tabela; /* informa o número de linhas da tabela */
> SELECT round(3.14159,2); /* arredonda o número para duas casas decimais */
> DELETE FROM nome_da_tabela WHERE definição_where; /* excluir linha que contenha a condição "definição_where" */
> UPDATE nome_da_tabela SET campo1 = valor1, campo2 = valor2;
> TRUNCATE table 'NomeDaTabela'; /* joga fora tabela zerando id mas sem jogar estrutura fora */
> SHOW FIELDS FROM nome_da_tabela; /* exibir estrutura da tabela */
> DESCRIBE nome_da_tabela; /* exibir estrutura da tabela */
> ALTER TABLE nome_da_table RENAME novo_nome; /* renomeia tabela */
> UNNEST(datas) /* expandir um array para um conjunto de linhas */
> EXTRACT('month' FROM unnest(datas)) /* retornar uma única parte de uma data / hora, como ano, mês, dia, hora, minuto, etc */
> UNNEST(datas)::date /* a sintaxe de dois pontos dobrados "::" serve para conversão de tipo; no caso, transforma em "date" */
> SELECT * FROM table WHERE data >= DATE_SUB(NOW(), INTERVAL 1 HOUR); /* Selecionar os dados da última hora*/
> SELECT * FROM nome_da_tabela group by data having count(*) >= 2; /* verifica se tem linhas com a mesma data, duplicadas */
A palavra DISTINCT pode ser usada depois de SELECT para retornar apenas valores diferentes. A cláusula WHERE permite diversas combinações usando AND, OR, BETWEEN e NOT BETWEEN, IN (quando os valores consideráveis estão dentro de um array), LIKE (considerar parte de uma string) e NOT LIKE. A cláusula ORDER BY permite ordenar por colunas de modo ASC (crescente) ou DESC (decrescente).
Caso queira atualizar uma linha se ela existir ou atualizar caso ela não exista, não é possível utilizar tudo em uma só query em SQL puro. Então pode-se deletar a linha contendo as condições especificadas e inserir uma nova linha em uma segunda query.
Relações entre tabelas
Às vezes surge a necessidade de pesquisar informações específicas, em um subconjunto dos dados com algumas restrições. Nesse caso, é possível criar “subtabelas” (ou subqueries) para realizar consultas – também chamado de “select aninhado”. No exemplo abaixo, é realizada uma busca (colocada entre parênteses) cujo resultado é “guardado temporariamente” como tb.
Para ilustrar como uma subquery funciona (primeira linha), segue um exemplo que faz a mesma busca mas sem utilizar esse recurso (segunda linha):
SELECT data,AVG(valor) as valormed FROM observados WHERE data BETWEEN '2015-08-15' AND '2015-08-16' AND (idcidade = 7293 OR idcidade = 7385) GROUP BY data;
SELECT data,AVG(valor) as valormed FROM (SELECT * FROM observados WHERE data BETWEEN '2015-08-15' AND '2015-08-16') tb WHERE (idcidade = 7293 OR idcidade = 7385) GROUP BY data;
Essa busca seleciona os dados entre as datas que pertençam a alguma das cidades informadas e são calculadas médias entre os valores observados nas cidades para cada dia, retornando um valor médio para cada data. Dica: a busca “idcidade” pode ser realizada também como “WHERE idcidade IN (7293,7385)” e a data em uma timestamp pode ser localizada também como “DATE(data_modelo) = ‘2015-08-15′”, por exemplo. Observe que o valor médio é guardado em uma coluna nomeada como “valormed”.
A cláuslua GROUP BY agrupa as células que possuam uma mesma característica (no exemplo acima, que tenham a mesma data). Usada em parceria, a cláusula HAVING determina uma condição de busca para um grupo ou um conjunto de registros, definindo critérios para limitar os resultados obtidos a partir do agrupamento de registros (semelhante ao WHERE). O modificador WITH ROLLUP logo após o GROUP BY calcula subtotais para as linhas que foram agrupadas e um total geral.
Nesse outro exemplo, na tabela temporária tb é que ocorre a busca descrita no início e final, onde é calculada a média dos preços cujas datas de venda estejam entre 2015-01-15 e 9 meses depois dessa data. Já a tabela tb selecionava a cidade e a data de entrada do produto entre cinco dias antes de 2015-01-15 e a própria data.
SELECT cidade, data_entrada, mes, ano, AVG(preco) as preco FROM
(SELECT cidade, data_entrada::date, unnest(data_venda)::date as data_venda,
extract('month' FROM unnest(data_venda)) as mes, extract('year' FROM unnest(dataprevisao)) as ano,
unnest(preco) as preco FROM vendas WHERE cidade = 7548 AND
data_entrada BETWEEN '2015-01-15'::date - interval '5 days' AND '2015-01-15') tb
WHERE data_venda BETWEEN '2015-01-15' AND '2015-01-15'::date + interval '9 months'
GROUP BY data_entrada, mes, ano, cidade;

Esse tipo de query gigante tem a vantagem de realizar somente uma busca/conexão ao banco, sendo mais rápido do que várias consultas individuais. Uma outra forma de relacionamento entre tabelas é o JOIN (do inglês “juntar”). Supondo uma tabela de categorias de produtos e outra com os produtos e registros de vendas, veja algumas formas de uni-las:
- RIGHT JOIN – retorna todos os produtos que pertencem categorias existentes e também o nome das outras categorias que não tem ligação com nenhum produto
- LEFT JOIN – o oposto do RIGHT JOIN
- INNER JOIN – omite dos resultados se houver um produto sem categoria ou a categoria não existir na tabela “categorias”
- OUTER JOIN – o contrário de INNER JOIN (os campos sem valor recebem NULL)
Veja um exemplo de uso:
SELECT `produtos`.* FROM `produtos`
INNER JOIN `categorias` ON `produtos`.`categoria_id` = `categorias`.`id`
ORDER BY `produtos`.`nome` ASC
Nesse caso, são selecionadas todas as colunas da tabela “produtos” unindo a tabela “categorias” onde a coluna “categorai_id” (da tabela “produtos” for igual à coluna id (da tabela “categorias”) ordenado pelo nome em ordem ascendente (alfabética).
O operador UNION combina o resultado de execução das duas queries e então executa um SELECT DISTINCT a fim de eliminar as linhas duplicadas. Já o UNION ALL apresenta mesmo as linhas duplicadas.
Uma View (ou também “virtual table”) é um objeto que pertence a um banco de dados, definida baseada em declarações SELECT´s, retornando uma determinada visualização de dados de uma ou mais tabelas. As Views são atualizáveis e podem ser alvos de declaração INSERT, UPDATE e DELETE, que na verdade modificam sua “based tables”.
As Stored Procedures (ou Procedimentos Armazenados) são rotinas escritas e armazenadas em arquivos capazes de executar várias ações no banco de dados a partir de uma única instrução. Já os Triggers (gatilhos) são objetos do banco de dados que, relacionados a certa tabela, permitem a realização de processamentos em consequência de uma determinada ação como, por exemplo, a inserção de um registro.
Funções (usando Linguagem procedural SQL) obrigatoriamente devem retornar dados (diferentemente das Stored procedures, que não retornam dados). Ambas ficam guardadas na base de dados para outros usos – se for atualizá-la, deve-se apagá-la usando o comando DROP. Caso vá executar somente uma vez ou prefira centralizar os códigos em um mesmo documento, é preferível usar um script SQL (arquivo ASCII com extensão .sql gravado separadamente) com as rotinas escritas em SQL. A execução de um arquivo “.sql” em linha de comando se dá através de:
$ mysql -h localhost -u root -pSENHA NOME_DB < nome_script.sql
Backup e transporte de base de dados
Caso necessite transportar/atualizar a base de dados de um computador para outro, existe o comando em terminal chamado mysqldump. Utilizado na máquina de origem, ele gera um arquivo .sql para ser levado à máquina de destino. Veja o comando (depois do nome da database, pode por o nome da tabela, se quiser uma tabela só:
$ mysqldump -u root -p nome_da_database nome_da_tabela > backup.sqlNa linha de comando do MySQL, deve-se criar uma base de dados vazia com mesmo nome da original:
> CREATE DATABASE nome_da_database;Para inserir os dados do arquivo de backup na base de dados criada, volte ao terminal do Linux e digite o seguinte comando:
$mysql -u root -p -A nome_da_database > backup.sqlExportar tabela para arquivo “csv”
Arquivos em formato csv (Comma-separated values) são em formato ASCII e dispõe os campos separados por um caracter comum (vírgula, por exemplo) e as linhas separadas por outro caractere (geralmente “\n”), e podem ser abertos em editores de planilhas, como o Microsoft Excel. Para exportar as informações em um arquivo “.csv”, selecione os dados através do seguinte comando:
> SELECT * FROM dados WHERE data like '%2014%' INTO OUTFILE '/tmp/dados2014.csv' FIELDS TERMINATED BY ',' LINES TERMINATED BY '\n';Os dados foram selecionados da tabela “dados” somente os campos que contenham “2014” (opcional) para o arquivo “/tmp/dados2014.csv”. Para importar os dados do arquivo csv:
> LOAD DATA LOCAL INFILE '/home/viniroger/dados2014.csv' INTO TABLE dados FIELDS TERMINATED BY ',' ENCLOSED BY '"' LINES TERMINATED BY '\n' (referencia,conjunto,valor,datahora);Note que os campos serão encapsulados por aspas duplas (“) na tabela “dados”.
Obs: caso os dados a serem selecionados estejam com o formato “date”, o LIKE não funciona, sendo o melhor método extrair o ano (e o mês) e comparar com o valor desejado. Por exemplo:
SELECT * FROM dados WHERE (EXTRACT(YEAR FROM data) = 2014 AND EXTRACT(MONTH FROM data) = 08);
Veja aqui tutorial sobre o MySQL, um Manual de MySQL muito bom e um curso online gratuito no youtube:
phpMyAdmin
O phpMyAdmin é um Aplicativo Web desenvolvido em PHP para administração do MySQL pela Internet. A partir deste sistema é possível criar e remover bases de dados, criar, remover e alterar tabelas, inserir, remover e editar campos, executar códigos SQL e manipular campos chaves. Essa interface gráfica é muito útil e agiliza muitos procedimentos. Veja mais sobre a instalação e configuração do phpMyAdmin no Debian.
Integração com PHP
Existem várias funções em PHP para executar comandos no MySQL. Por exemplo, Mysql_close() se usa para fechar a conexão ao Banco de dados (necessária para não sobrecarregar o servidor) e Mysql_free_result() se usa para liberar a memória empregada ao realizar uma consulta. Algumas funções estão em vias de depreciação, sendo recomendado utilizar “mysqli” ou “POD_MySQL”. Veja o artigo no PHP.net e alguns exemplos:
// Conexão a uma base de dados por um usuário em um host usando senha
$link = mysql_connect ($hostdb, $userdb, $passdb, $namedb); //antes
$link = new mysqli($hostdb, $userdb, $passdb, $namedb); //depois
// Exibindo mansagem de erro
die('Could not connect: ' . mysql_error()); //antes
printf("Connect failed: %s\n", mysqli_connect_error()); //depois
// Execução de "query" (comando MySQL)
$result = mysql_query($strQuery); //antes
$result = mysqli_query($link,$strQuery); //depois, precisa do link antes!
// Liberar memória
mysql_free_result($result); //antes
mysqli_free_result($result); //depois
// Fechar conexão
mysql_close($link); //antes
mysqli_close($link); //depois
// Retorna uma matriz associativa que corresponde a linha obtida e move o ponteiro interno dos dados adiante
$row = mysql_fetch_assoc($result); //antes
$row = $result->fetch_assoc(); //depois
// Busca o resultado de uma linha e o coloca como uma matriz
$row = mysql_fetch_array($result, MYSQL_BOTH); //antes
$row = $result->fetch_array(MYSQLI_BOTH); //depois
// Retorna o número de linhas em um resultado
$count = mysql_num_rows($result); //antes
$count = mysqli_stmt_num_rows($result); //depoisVeja também o post sobre PostgreSQL clicando no link.

4 comments