Nesse texto, será explicado como baixar um arquivo HDF para trabalhar com um script em python. Nele, o arquivo deve ser lido e extraído um subconjunto, que representa uma área delimitada pelo usuário, e calculada a média de uma variável também definida pelo usuário.
Donwload do arquivo HDF
O arquivo a ser baixado contém dados do sensor MODIS, a bordo dos satélites Terra e Aqua. Os produtos estão disponíveis para o público a partir do site da NASA (LAADS DAAC) em arquivos HDF (Hierarchical Data Format). Nesse caso, serão usados dados de nível 3 e somente do satélite Terra, ou seja, prefixo MOD08_D3. Para baixar o arquivo de exemplo, entre no site da NASA, busque pelo prefixo, selecione o item resultante da pesquisa, preencha o dia (1º de junho de 2009), localização (limitado pelas latitudes 5°N e 16°S e pelas longitudes 75°W e 46°W, o que cobre boa parte da Floresta Amazônica) e selecione o arquivo – ou simplesmente acesse o link para download do arquivo MOD08_D3.A2009152.061.2017299185107.hdf.
Os dados de nível 1 contêm os dados de radiância calibrados e possui dados de georeferenciamento, que descrevem a localização, geometria de iluminação e geometria de observação para cada pixel. Os produtos de nível 2, cuja resolução espacial varia de 1 x 1 km a 10 x 10 km, são gerados a partir dos dados de nível 1 ao passar por um conjunto de algoritmos, resultando nos produtos de nuvens, aerossóis e outros.
Já os dados de nível 3 são baseados em médias ponderadas dos produtos de nível 2 de aerossol, nuvens e perfil atmosférico e possuem resolução espacial de 1° x 1°. Em cada arquivo diário, os produtos são apresentados em termos de estatística básica (média, desvio padrão, valores máximos e mínimos).
Configuração do ambiente de trabalho
Uma possibilidade de uso do python e de suas bibliotecas é através do miniconda e ambientes virtuais – clique no link para ver mais. Com o miniconda instalado, é preciso criar um ambiente virtual (nesse exemplo, chamado “modis”), ativá-lo, instalar o python (nesse exemplo está para instalar a última versão, mas ela pode ser especificada) e as bibliotecas necessárias (numpy e pyhdf, nesse caso). Os comandos a seguir, a serem executados no terminal, dão conta da tarefa:
conda create -n modis
conda activate modis
conda install python
conda install numpy
conda install -c conda-forge pyhdf
Manipulação e execução de script
O código a seguir foi desenvolvido com base no publicado no HDF-EOS, que também usa os pacotes matplotlib e cartopy para plotar o mapa da variável (opção não usada aqui). Os campos FILE_NAME e DATAFIELD_NAME informam o nome do arquivo usado e a variável de interesse. Para ver os nomes de outras variáveis, existe um trecho do código comentado como “Print dataset” que pode ser descomentado para imprimir os nomes de todos os conjuntos de dados – são muitos campos, então é melhor direcionar a saída da execução do script para um arquivo.
Além das variáveis acima, também deve-se definir a área a ser selecionada pelo script – essa parte do código foi inspirada na questão do stackoverflow, Numpy extract subset of grid data, e será melhor explicada mais adiante. Seguindo no código: após a leitura do arquivo, são lidas as variáveis de latitude (‘XDim’) e de longitude (‘YDim’), convertidas para variáveis tipo “double”. Então é lido o dataset escolhido e os respectivos atributos de nome, offset, valor nulo, fator de escala e unidade, respectivamente. Com eles, são calculados os reais valores e criada uma máscara que exclui os valores nulos.
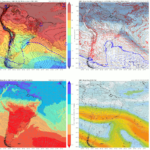
O bloco seguinte de código é o responsável por selecionar o grid de dados. A área selecionada é informada pelas variáveis mLat (latitude mínima), MLat (latitude máxima), mLon (longitude mínima) e MLon (longitude máxima) no início do script. No exemplo, essa área corresponde a um quadrado de 5°x5° compreendendo Manaus e região, conforme a figura a seguir:
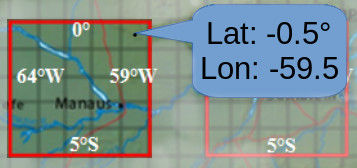
Como o produto de nível 3 dispõe os dados em quadrados de 1°, temos uma correspondência direta entre posicionamento de pixel de dado e sua posição em latitude/longitude, o que é ilustrado na figura acima. Na área selecionada, são 25 quadrados de 1° x 1° e delimitados por números inteiros que representam as latitudes e longitudes.
Como informações de espaço, temos dois vetores (formato “numpy array”): lat e lon, com 180 e 360 valores respectivamente. Quanto aos dados de interesse, existe uma matriz de dimensões 180 x 360 pixels chamada “datam”. Essas informações devem ser unidas de modo a criar uma única grade, na qual cada ponto tenha três valores: latitude, longitude e valor. Esse é o objetivo do método meshgrid do NumPy. Seu uso cria duas matrizes de dimensões 180 x 360 pixels: Lats e Lons.
O próximo passo é fazer uso do método where do NumPy para os índices de elementos em uma matriz de entrada onde a condição dada é satisfeita. Ou seja, a variável “indexes” contém dois vetores indicando a posição (linhas e colunas) dos pixels selecionados. Nesse caso, são os pixels entre as linhas 90 e 94 e as colunas 116 e 120.
De posse dessas posições na matriz, esses pixels correspondem tanto aos valores de lat/lon da região selecionada quanto aos valores da variável selecionada para essa região. Assim, a variável “subData” recebe a matriz referente a essa seleção. Nessa matriz que deve ser aplicado o método de cálculo da média dos valores internos (último bloco de código) e outros que podem ser implementados (como desvio padrão).
#!/usr/bin/env python3.10.8
# -*- Coding: UTF-8 -*-
FILE_NAME = 'MOD08_D3.A2009152.061.2017299185107.hdf'
DATAFIELD_NAME = 'Cloud_Fraction_Mean'
# Boundaries: m - min ; M - max
mLat = -5
MLat = 0
mLon = -64
MLon = -59
import numpy as np
from pyhdf.SD import SD, SDC
# Load file
hdf = SD(FILE_NAME, SDC.READ)
# Print datasets
#datasets = hdf.datasets()
#print(datasets)
#exit()
# Read lat/lon
xdim = hdf.select('XDim')
lon = xdim[:].astype(np.double)
ydim = hdf.select('YDim')
lat = ydim[:].astype(np.double)
# Read dataset
data_raw = hdf.select(DATAFIELD_NAME)
data = data_raw[:,:].astype(np.double)
# Retrieve attributes
attrs = data_raw.attributes(full=1)
lna = attrs["long_name"]
long_name = lna[0]
aoa = attrs["add_offset"]
add_offset = aoa[0]
fva = attrs["_FillValue"]
_FillValue = fva[0]
sfa = attrs["scale_factor"]
scale_factor = sfa[0]
ua = attrs["units"]
units = ua[0]
# Retrieve dimension name
dim = data_raw.dim(0)
dimname = dim.info()[0]
# Calculate actual values
data[data == _FillValue] = np.nan
data = scale_factor * (data - add_offset)
datam = np.ma.masked_array(data, np.isnan(data))
# Extract subset of grid data
Lons, Lats = np.meshgrid(lon, lat)
indexes = np.where((Lons < MLon) & (Lons > mLon) & (Lats < MLat) & (Lats > mLat))
subLons = Lons[indexes]
subLats = Lats[indexes]
subData = datam[indexes]
# Calculate subset statistics
mean_val = subData.mean()
print(mean_val)
Para executar o script, copie o conteúdo e cole em um bloco de notas, podendo ser salvo com o nome “read_hdf.py”. Para executá-lo no terminal, digite o comando “python read_hdf.py” e dê ENTER. Lembrando que deve estar com o ambiente virtual ativado, o que pode ser feito através do comando “conda activate modis” caso não esteja aparecendo o nome desse ambiente entre parênteses logo no início da linha de execução do terminal.