O perfil desejado de um cientista de dados é de alguém que entenda de ciências da computação (principalmente programação e banco de dados de alta performance), que saiba de estatística, economia e administração. Como ninguém sabe a fundo todas essas áreas do conhecimento, o que acontece é formar uma equipe com pessoas que saibam profundamente alguma das áreas e com noção nas outras.
Dentre as áreas de conhecimento técnico necessárias, estão:
- Programação Paralela e Distribuída: é comum o uso de muitos dados ou a repetição de algoritmos muito custosos do ponto de vista de processamento.
- Bancos de dados: ainda é muito comum o uso de banco de dados relacional (como os “SQL”), mas para projetos com um número muito grande de dados (os chamados Big Data), é cada vez mais usado o banco de dados não relacional (como o MongoDB).
- Ferramentas de Coletas de Dados: uso de programas ou scripts automatizados que escaneiam páginas Web para indexa-las ou mesmo procurar e coletar algum conteúdo específico (processo chamado de Coleta ou Web Crawling).
- Algoritmos e Linguagens de Programação: Python e R estão no topo das mais requisitadas, mas JAVA e outras também são muito usadas conforme o nicho de desenvolvimento.
- Computação em Nuvem: com essa tecnologia é possível usar processamento e armazenamento por demanda em grandes servidores (como Amazon, Microsoft Azure e Google), devido ao seu custo menor, facilidade de manutenção, expansão e configuração e, principalmente, alta disponibilidade.
- Sistemas Operacionais: o profissional lida diretamente com diversos sistemas operacionais, sendo mais comum Linux e Windows.
Para atender esse novo conjunto de exigências técnicas, surgiu um novo perfil denominado Cientista de Dados. Atualmente, o mais comum é formados em ciências da computação e carreiras de Exatas absorverem essas vagas. Mas uma característica é extremamente desejada: a de ser um bom cientista. Isso envolve: saber mexer com os dados, ter uma metodologia de trabalho para experimentar/documentar/implementar, enfrentar novos problemas (principalmente quando não tem uma solução já estabelecida) e gostar de aprender.
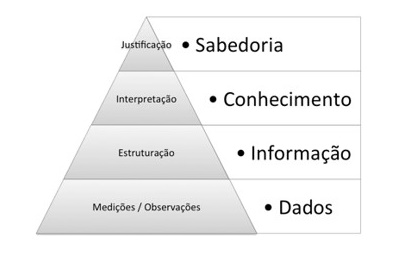
A preparação dos dado (DataPrep) é uma das tarefas mais trabalhosas e importantes do processo de construção do conhecimento e modelagem, para depois aplicar o modelo na categorização ou previsão de novas informações.
Dentre os problemas mais comuns, estão: escalas diferentes, outliers, ruído e séries incompletas. Para minimizar o efeito desses problemas, deve-se primeiramente fazer uma análise explanatória dos dados, com a visão de um especialista da área. Deve-se verificar se as variáveis tem distribuição normal, o quanto de correlação possuem e fazer gráficos de série temporal, categorias, box-plot e histogramas.
Depois, partir para a limpeza dos dados, integração das informações, redução (só copiar as variáveis e períodos que seja interessante trabalhar) e discretização. Pode-se excluir as colunas de variáveis com muitas falhas ou completar os valores ausentas das séries inserindo uma constante (média ou mediana, por exemplo), valores aleatórios, interpolação, preencher por lógica (por exemplo, sempre que chove não tem observação de tal variável) ou mesmo prevendo valores.
Uma dupla de amostras com grande desbalanceamento (muitas de um tipo e poucas de outro) também precisa ser imposto um equilíbrio. Ordens de grandeza muito diferentes fazem necessária uma transformação, como uma normalização (depois de separar grupo de teste e de treino).


One comment