Caso você precise escrever um artigo e submetê-lo para avaliação dos pares em uma revista científica, uma opção muito comum é usar o LaTeX para formatação. Uma plataforma online muito usada nesse contexto é o Overleaf, mas que apresenta restrições de uso gratuito para arquivos que exigem muito processamento. Esse post apresenta uma alternativa instalando programas no próprio computador Linux e usando modelos para gerar o PDF.
Um outro post fala sobre submissão de artigo Elsevier com foco no processo em si e considerando um artigo single blind, mas aqui será gerado um artigo double blind. Na revisão (peer review) do tipo single blind, os revisores conhecem a identidade dos autores enquanto os autores não sabem quem são os revisores; na revisão double blind, nem revisores nem autores conhecem a identidade uns dos outros. Nesse caso, ao enviar o manuscrito na plataforma “Editorial Manager” da Elsevier, aparece uma mensagem assim:
“Manuscript WITHOUT Author Identifiers: please ensure the Manuscript file has no information that could allow reviewers to identify any of the authors; see What are the requirements for double-blind peer review? for more details.”
Em uma revisão duplo-cega, a página de título (“title page”) permanecerá separada do manuscrito durante todo o processo de revisão por pares e não será enviada aos revisores. Ela deve incluir:
- O título do manuscrito
- Os nomes e afiliações de todos os autores
- O endereço completo do autor correspondente, incluindo um endereço de e-mail
- Agradecimentos (verifique o “Guide for authors” da revista, pode ser exigido que não seja enviado aí)
- Declaração de interesses (caso não seja solicitado o documento em separado)
Devem ser removidas quaisquer informações de identificação, como nomes ou afiliações dos autores, do manuscrito antes do envio – mesmo em figuras ou tabelas. Além disso, use a terceira pessoa para se referir a trabalhos que os autores já publicaram. Exclua agradecimentos e quaisquer referências a fontes de financiamento; essa informações devem ficar na página de título ou em uma seção normal do .tex antes das referências quando o artigo for aceito, durante o envio do conjunto completo dos arquivos. Escolha os nomes dos arquivos com cuidado e certifique-se de que as “Propriedades” do arquivo também estejam anonimizadas. Todos os tipos de arquivo, exceto a Página de Título, a Carta de Apresentação e os Arquivos Fonte LaTeX, geralmente estão incluídos na versão do manuscrito compartilhada com os revisores.
Instalação
Considere aqui a instalação do LaTeX em um computador Linux Debian. Como sua versão completa pode ocupar por volta de 6GB de disco, talvez seja interessante instalar somente o básico e depois ir incluindo alguma coisa extra que precisar. Por exemplo, o pacote “texlive-lang-portuguese” para garantir hifenização e suporte linguístico adequado. A sugestão aqui (artigos em inglês) é a seguinte:
sudo apt install texlive texlive-latex-extra latexmk
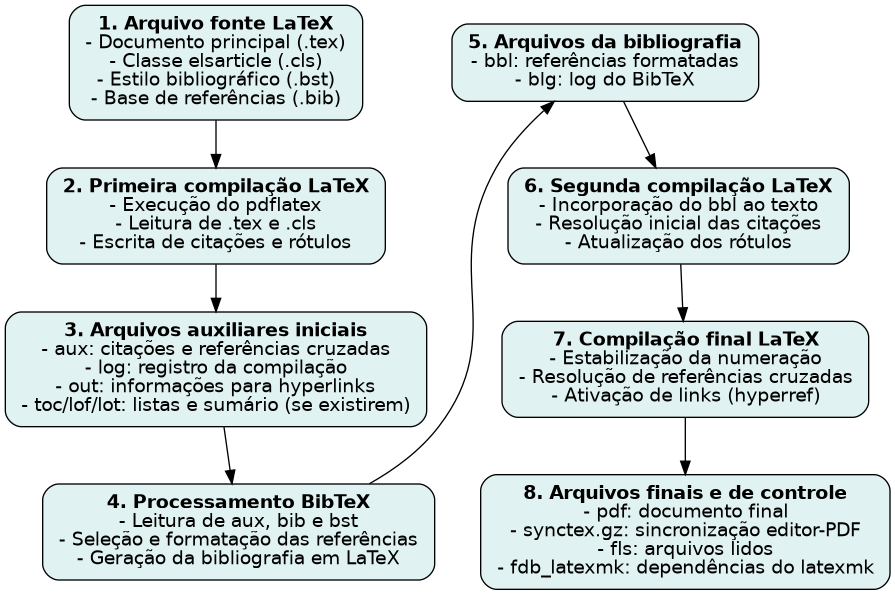
O latexmk é uma ferramenta de automação para compilação de documentos LaTeX que detecta automaticamente quais etapas são necessárias para gerar o PDF final. Ele executa o compilador apropriado (pdflatex, xelatex ou lualatex) e chama ferramentas auxiliares como BibTeX ou Biber sempre que há citações, referências cruzadas, listas de figuras ou tabelas pendentes.
A principal vantagem de usar o latexmk em documentos com citações é que ele gerencia automaticamente as múltiplas compilações exigidas pelo LaTeX, garantindo que referências e citações fiquem corretas sem que o usuário precise rodar comandos manuais repetidos, reduzindo erros e tornando o processo de compilação mais robusto e reprodutível. Dessa forma, basta usar o seguinte comando para compilar seu arquivo LaTeX:
latexmk -pdf nome_do_arquivo.tex
Edição de arquivos
Você pode usar o VS code para trabalhar com os arquivos – com suporte a syntax highlighting, versificação de código, etc. Por padrão, o VS Code não quebra linhas em .tex, o que é chamado de “word wrap”, mas mostra cada linha como está no arquivo. Para ativar essa quebra de linhas nessa sessão, você pode usar ALT+Z, mas quando reabrir você deverá reativá-la. Para sempre ter quebra automática de linha em arquivos .tex:
1. Vá em File → Preferences → Settings (ou Ctrl+,) e selecione o ícone de papel com uma seta no canto direito superior (passando o mouse em cima, aparece o texto “Abrir configurações (JSON)” – isso abre o arquivo settings.json;
2. Adicione o seguinte código (sem as barras invertidas):
{
"\[latex\]": {
"editor.wordWrap": "on"
}
}
Se já houver conteúdo, insira somente o bloco interno (sem as chaves mais externas) dentro das chaves do JSON existente.
Scripts
O modelo utilizado aqui partiu do template da Elsevier no Overleaf, que contém os seguintes arquivos principais (os tipos podem ser harv, num ou num-names):
- cas-refs.bib: Contém as referências em formato BibTeX (o programa bibtex usa o conteúdo desse arquivo para gerar a lista final de referências enquanto que o pacote do LaTeX chamado natbib cuida das citações dessas referências no texto).
- elsarticle.cls: Classe do documento, define layout (duas colunas, margens, fontes), comandos específicos da Elsevier (\author, \affiliation, \corref, etc.) e qual sistema de citações é esperado.
- elsarticle-num-names.bst: Define como a referência aparece na lista final e como natbib deve se comportar no texto ao citar as referências.
- elsarticle-template-num-names.tex: Arquivo principal onde o artigo é escrito.
Aqui foi usado como base o arquivo elsarticle-template-num-names.tex (veja mais sobre os tipos dos arquivos de citações no início do post Submissão de artigo Elsevier). O template elsarticle-num-names usa o natbib, mas força um estilo puramente numérico; portanto, comandos autor-texto (\citet) são reduzidos a números pelo .bst, e isso é comportamento correto e esperado. Basicamente, ele define a questão de citação/referência da seguinte forma:
\documentclass[preprint,12pt]{elsarticle} % sem opção de citação explícita, assume o padrão (citação numérica)
\bibliographystyle{elsarticle-num-names} % usa arquivo elsarticle-num-names.bst (estilo numérico com nomes dos autores explícitos na lista de referências)
Os scripts e sua documentação estão disponíveis no repositório no Github: viniroger/paper_latex. Existe uma versão com todos os arquivos a serem gerados (Title page, Highlights e Manuscript) em um mesmo documento (e que gera um só PDF): elsarticle-double-blind.tex. No entanto, os arquivos separados é que funcionam na geração do DOCX (e que geram os arquivos separadamente para envio na plataforma): titlepage.tex, highlights.tex e manuscript.tex. A sugestão é para trabalhar em somente um dos casos, conforme sua necessidade.
Para gerar a versão já revisada (tanto do PDF quando do LaTeX) para envio à editora para publicação, basta descomentar os trechos de código marcados como “UNCOMMENT to final version” no arquivo manuscript.tex:
- author, ead e affiliation
- highlights
- acknowledgements
O repositório também contém o script “texcount.pl” para contar o número de palavras do documento por texto, títulos, legendas de figuras/tabelas, assim como por seções. Das estatísticas apresentadas, a quantidade de palavras do texto principal (corpo do artigo) é indentificada como “Words in text” – não inclui referências. Por exemplo, se a revista pede “original papers should be between 4000 and 6000 words (excluding table/figure captions and references)”, ela quer apenas o texto principal + títulos das seções.